摘要:大型语言模型在通用的聊天方面取得了令人印象深刻的性能。然而,在特定领域的专业能力,特别是在信息提取方面,它们仍然存在一定的局限性。从非标准模式或指令中提取结构化信息对于过去的提示方法来说已经证明具有挑战性。因此,我们探索了在聊天语言模型中使用领域特定建模来解决从自然语言中提取结构化信息的问题。在本文中,我们提出了ChatUIE,这是一个创新性的统一信息提取框架,建立在ChatGLM之上。同时,强化学习被应用于各种涉及混乱和有限样本的任务,以提高各个任务的性能。此外,我们还整合了生成约束,以解决在生成输入中不存在的元素的问题。我们的实验结果表明,ChatUIE可以显著提高信息提取的性能,同时聊天能力略有下降。
本文内容:作者基于ChatGLM,设计了一个奖励模块。使用强化学习提升聊天模型在专业领域提取结构化信息的性能。
相关概念:
Supervised Fine-Tuning(监督式微调)
定义: SFT 是在一个已经预训练的模型上,利用特定任务的标注数据进行再训练的过程。这种方法依赖于有标签的数据集来指导模型学习。
目的: SFT 的目标是使预训练的模型更好地适应于一个具体的任务,通过学习任务相关的特征来提高模型在该任务上的性能。
方法: 通过最小化预测输出和实际标签之间的差异(例如,使用交叉熵损失函数)来进行参数更新。
应用场景: SFT 适用于各种有明确标签的监督学习任务,如分类、回归、信息提取等。
Reward Model(奖励模型)
奖励模型是在强化学习框架中用来评估代理(agent)行为好坏的模型。在特定的上下文和行为下,它为代理提供了一个奖励信号,这个信号反映了当前行为对达成目标的效用。在信息提取等任务中,奖励模型可以帮助评估生成的输出(如提取的信息)与期望输出的一致性,从而指导模型进行更优的行为选择。
Reinforcement Learning(强化学习)
定义: 强化学习是一种通过奖励(或惩罚)信号来引导模型学习如何在给定环境中采取行动以最大化累积奖励的方法。它不依赖于有标签的数据集,而是通过探索和利用环境反馈来学习。
目的: 强化学习的目标是学习一个策略,该策略能够指导代理(agent)在特定环境中做出决策以最大化长期奖励。
方法: 通过试错(trial-and-error)、策略评估和优化来进行学习。代理根据其行为获得的奖励或惩罚来调整其行为策略。
应用场景: 强化学习适用于决策制定、游戏玩法、机器人控制、推荐系统等领域,尤其是在那些可以通过与环境交互来获得反馈的场景。
Logits
logits一词通常指模型输出层的原始预测值,即在应用激活函数(如softmax)转换为概率之前的值。在本文引用中,logits代表了模型在对给定输入进行处理并生成预测时的原始输出。
EOS
EOS指的是“序列结束(End of Sequence)”,这是一种特殊的标记或符号,用于指示文本序列或输入数据的结束。在自然语言处理(NLP)任务和模型中,EOS标记可以帮助模型识别输入或输出序列的边界。在生成任务或序列预测任务中,模型需要知道何时停止生成更多的输出,EOS标记就是这一停止信号。
$y_{EOS}$
y_{EOS} 指的是序列结束(EOS)标记的logits值,将这个logits值用于标量奖励的计算,旨在区分正面和负面样本的奖励,进而优化模型性能。
Proximal Policy Optimization(PPO)
PPO是一种在深度强化学习领域广泛使用的算法,他由OpenAI在2017年提出,PPO算法通过优化一个特殊的目标函数来更新策略,这个目标函数考虑了新策略与旧策略之间的差异(即策略比例),并通过引入一个裁剪机制来避免更新步骤过大,从而提高学习的稳定性和效率。
KL-Div
KL散度(Kullback-Leibler divergence)是用于衡量两个概率分布之间差异的一种非对称度量。在强化学习部分,KL散度用于确保当前策略与参考策略(例如,经过监督微调后的策略)之间的差异保持在一定范围内。通过引入KL散度约束,可以避免新策略在训练过程中偏离初始策略太远,从而保证模型的稳定性和生成结果的合理性。
具体来说,KL 散度衡量了用一个概率分布 Q 来近似另一个概率分布 P 时的信息损失量。在许多机器学习任务和统计分析中,KL 散度用来衡量或优化模型的性能。
KL 散度的数学定义如下:
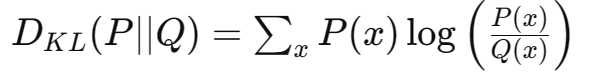
或者在连续变量的情况下:
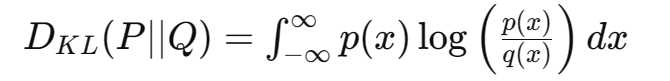
其中,P 和 Q 是两个概率分布,p(x) 和 q(x) 分别是这两个分布的概率密度函数。
模型架构:

SFT(Supervised Fine-Tuning)
在输入句子中,通过LLM识别类型为“Person”的实体,并生成响应。我们需要通过监督式微调,使预训练的大语言模型(LLM)更好的适应于一个具体的任务(如识别Person实体类型的对象)。
输入部分分为两部分:指令和上下文。
指令部分有M个标记,上下文部分有N个标记,它们都被GLM编码为向量表示x = [x_{i1}, \ldots, x_{iM}; x_{c1}, \ldots, x_{cN}] \in \mathbb{R}^{(M+N) \times D},D表示嵌入的维度。
每个标记生成的概率如下所示:
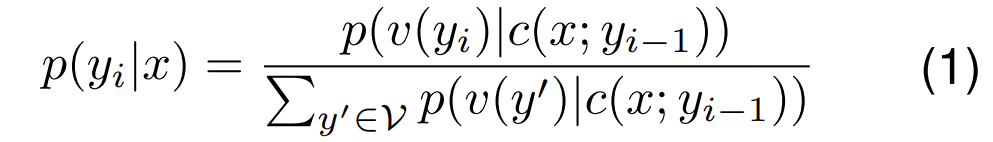
其中V代表一个包含130528个词汇的词汇表。v是一个多层感知器(MLP),c是GLM的解码器,c(x; y_{i-1})是给定上下文x和之前的输出yi-1时,模型的解码器输出。p(y_i|x) 的维度为R|V|,代表对于每一个单词表中的词 yi,都有一个与之对应的概率。
p(y_i|x)是条件概率,表示在给定输入x的情况下,单词yi发生的概率。p(v(y_i)|c(x; y_{i-1}))则是将词汇v映射到向量c(x; y_{i-1})的概率。这个解码向量由模型在当前时间步之前生成的words以及上下文信息计算得出。通过将yi词向量在上下文空间向量内的概率除以每一个词向量在上下文空间向量的概率和,得出单词yi发生的概率。
简而言之,我们需要计算单词yi在给定上下文下的概率,而这个概率由模型在当前时间步之前生成的words以及上下文信息计算得出。
损失函数:最大似然估计
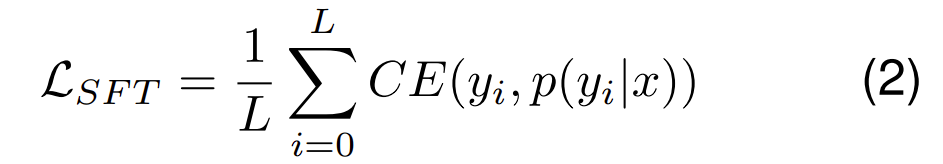
其中L表示目标序列长度,CE是交叉熵损失函数。
交叉熵损失函数衡量真实输出和预测输出之间的差异:
通过将所有的交叉熵损失函数相加再除以总序列长度L,得出一个代表预测输出值和实际输出的差值,通过最小化这个损失函数找到一个给定输入下最精确的输出序列。
RM(Reward model)
此模块接收输入并识别类型为“Person”的实体候选者,根据相关性分配奖励。
针对UIE(统一联合抽取)中类型混淆和不均匀的样本分布的问题,作者采用强化学习作为解决方案。在传统的SFT框架基础上引入了强化学习,以一条指令、一个上下文和一个正或负响应作为输入,以一个标量奖励作为输出。
输出标量奖励的计算公式:
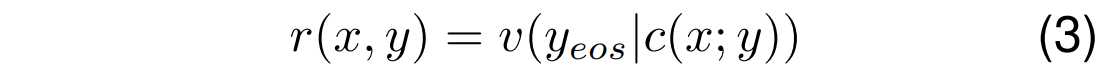
这个公式表示在强化学习中使用的奖励模型。这里,r(x,y) 表示给定输入x和输出y的标量奖励。函数 v(⋅) 计算给定上下文 x 和部分输出 y 时,结束符(EOS)标记的逻辑值(logits),使用模型的解码器 c(⋅) 进行计算。这个奖励对于训练模型以区分正负样本至关重要,提高模型生成准确且相关信息提取的能力。
为了更好的区分正负样本对,我们需要最大化正样本和负样本的奖励之间的差异。针对这个目标我们设计了这个损失函数:
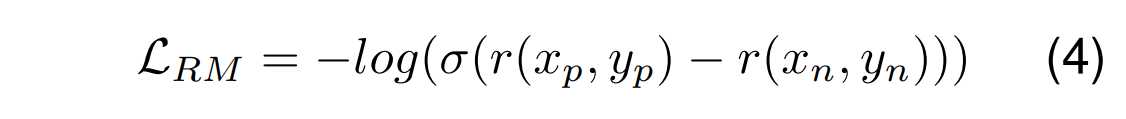
这里,σ 是sigmoid函数,它将奖励的差值映射到 (0, 1) 区间,通过负对数,这个目标鼓励模型增加对正样本 (这里,σ 是sigmoid函数,它将奖励的差值映射到 (0, 1) 区间,通过负对数,这个目标鼓励模型增加对正样本 (x_p,y_p) 的奖励,减少对负样本 (x_n,y_n)的奖励,从而有效地学习区分输出的质量。
RL (Reinforcement Learning)
在这个模块中,使用奖励通过logits和KL-Div训练模型,以优化实体识别。
与监督微调模型相反,奖励模型并不完全依赖于训练集中来自训练集的训练样本。训练样本的构建包括多种方法,其中一种方法是用不同类型的混淆替换样本结果以生成负样本,另一种方法是使用潜在语义分析(SFT)和ChatGPT模型预测外部类似数据集的提取结果。此外,ChatGPT还被用来评分提取结果,从而增加了有限的样本数据量。然后,强化学习采用PPO策略优化。最后,强化学习训练中的目标函数可以表达如下,通过最小化这个损失,训练模型在给定输入 x 下生成期望输出 y 的能力:
![图片上传中…]
r(x,y):这表示给定输入 x 和模型生成的输出 y 时的奖励值,是通过奖励模型 (RM) 计算得到的。奖励值衡量的是输出 y 的质量(与期望输出的一致性)。
β\log\left( \frac{p_{RL}(y|x)}{p_{SFT}(y|x)} \right)是引入的KL散度项。其中β是一个标量系数,用于调节KL散度项对损失函数的影响程度。KL散度则用于测量两个概率分布之间的差异。 \log\left( \frac{p_{RL}(y|x)}{p_{SFT}(y|x)} \right) 表示是模型在强化学习(RL)策略下生成输出y的概率p_{RL}(y|x)与在监督式微调(SFT)策略下生成输出的概率p_{SFT}(y|x)之间的对数比例。反应模型强化学习策略与监督式微调策略中的偏移量,反应模型行为的变化程度。
受KL-Div的启发,文章中p_{RL}(y|x)与p_{SFT}(y|x)可以视为两个概率分布,其中p_{RL}(y|x)类似于P(x),表示在强化学习策略下给定输入 x 时生成输出 y 的概率分布;而p_{SFT}(y|x)类似于Q(x),表示在监督式微调(Supervised Fine-Tuning, SFT)策略下给定输入 x 时生成输出 y 的概率分布。在这种情况下,KL 散度D_{KL}(P || Q)用于衡量在给定输入 x 的情况下,这两种策略产生的输出分布之间的差异,作者利用了这两个概率分布之间的差异作为计算强化学习的损失的一部分。
这个公式的目的是通过调整强化学习模型,使其在给定输入 x 下,能够更倾向于生成带来更高奖励 r(x,y) 的输出 y,同时引入KL散度,限制强化学习过程中策略的偏移,防止新的策略在学习过程中偏离初始策略太远,确保新策略与经过监督微调的初始策略保持一致性。KL散度项在训练过程中起到正则化的作用,防止策略更新幅度过大,从而稳定训练过程,避免模型陷入局部最优或出现剧烈波动。
通过调整系数 β 在策略的探索和利用之间取得平衡。较大的𝛽值会使策略更新更为保守,而较小的𝛽值则允许更大的策略探索。