论文工作
轻量化
作者认为:现有的模型微调方法需要对预模型所有的参数进行全量微调,然而,由于预训练模型具有巨量参数,将模型进行迁移应用计算量消耗过大。
作者基于此提出了一种轻量化微调方法FLAT,迁移下游任务时将原始模型的中间表征进行降维,仅微调分解得到的低秩矩阵,然后构建一个基于注意力机制的低秩融合网络,增强下游任务相关知识。融合后的表征经过适配器任务头并升维到原始维度。
信息抽取
作者认为:现有的信息抽取方法存在模型迁移性差,缺乏标签语义感知,依赖大量标注数据的问题。
作者基于此提出了一种轻量化知识注入的文本信息抽取模型。该模型利用FLAT模块向预训练语言模型注入领域知识,模块可以根据后续的任务中自由组合。在向信息抽取任务迁移的训练过程中,该方法通过通用信息抽取和指令微调的形式同时训练领域知识融合模块和信息抽取任务迁移模块,使多个领域的知识可以根据具体任务的需要动态地融合。
FLAT
模型架构
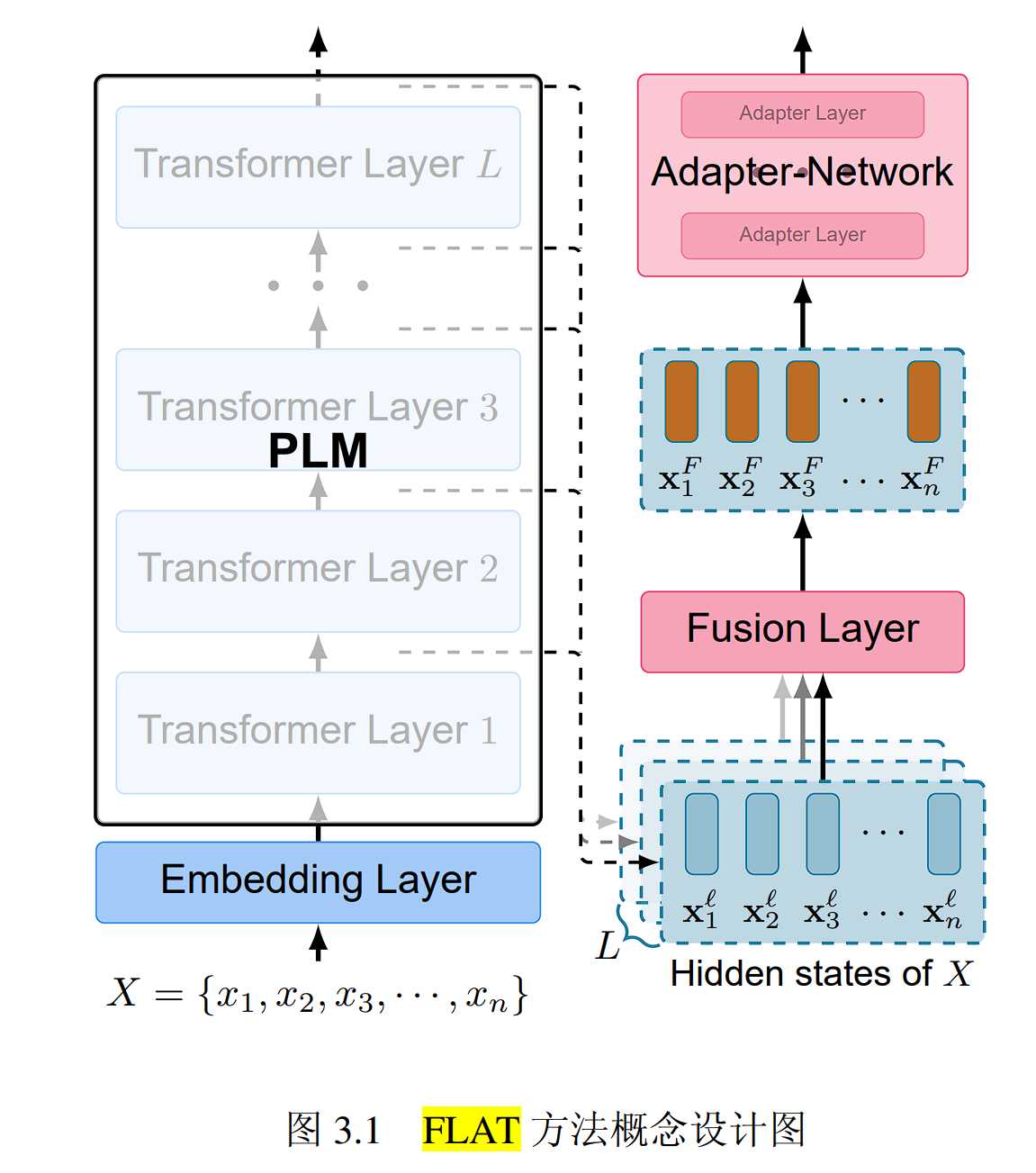
FLAT 方法由两个主要部分组成:
1. token粒度的基于注意力机制的知识融合层,该模块用于在低秩空间中对来自预训练语言模型的多样知识进行面向具体任务的融合
2. 轻量化的 Adapter 网络用于将融合后的具备丰富知识的语言表征迁移到任务所需的向量空间。为了在向下游任务迁移过程中充分考虑上下文信息,该模块采用 Transformer 结构
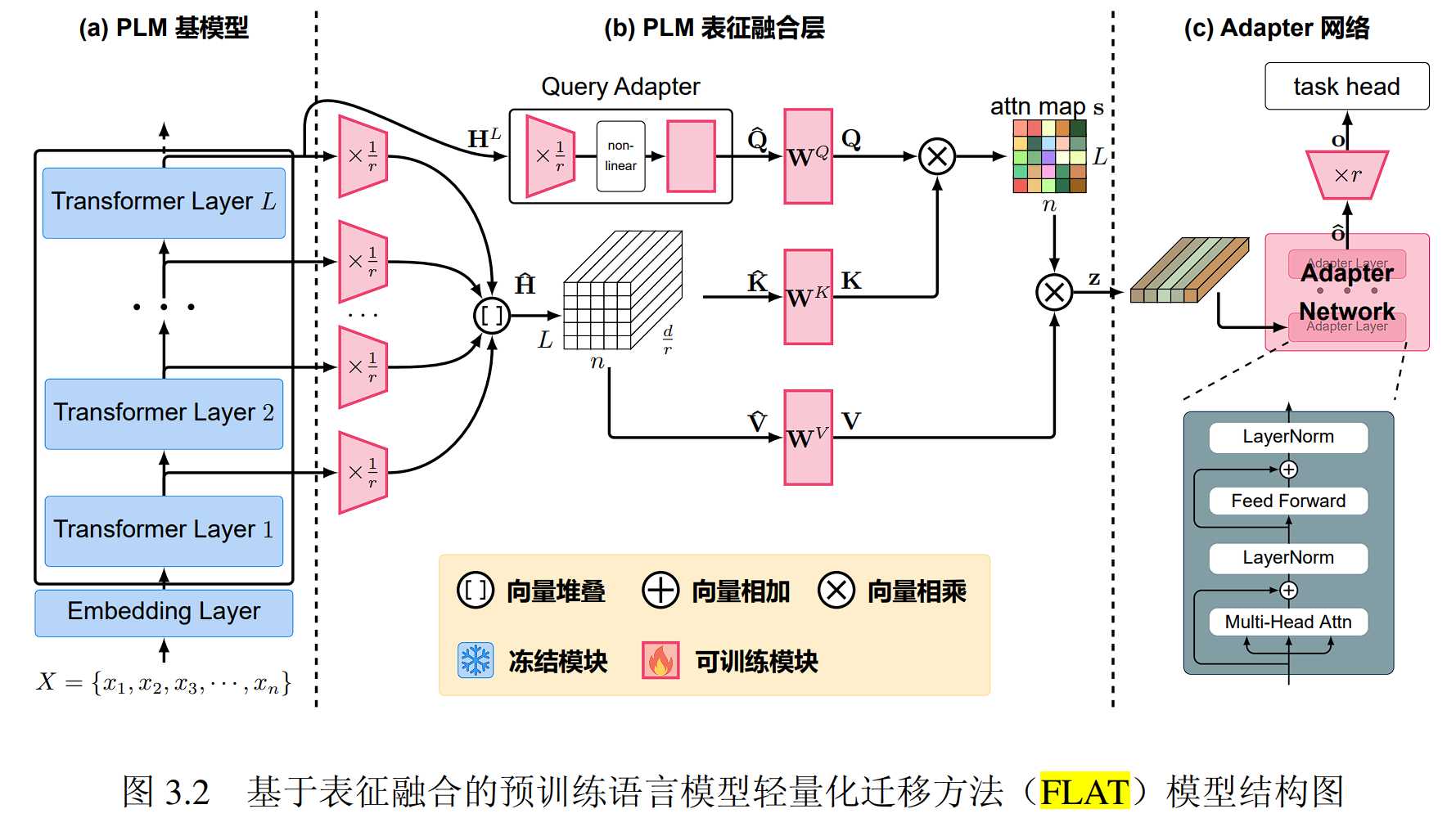
具体而言,输入文本首先经过预训练语言模型进行上下文表征,从基模型获取丰富的知识。随后,FLAT 方法取出基模型每一层的输出表征,并且将其按层分别通过独立的投影模块降维到低秩空间。在低秩空间中,Q 向量来自基模型最后一层输出的最终表征,K, V 则来自所有层的输出表征。由于预训练语言模型的最终表征在预训练过程中被直接用于预训练的任务,与下游实际任务相差很大,因此引入基于前馈神经网络的查询适配模块(Query Adapter)对Query进行处理。随后采用自注意力机制对QKV进行表征融合,经过融合后的表征向量最后经过轻量化的 Adapter 网络和具体任务所需的任务头网络适配分类、回归等下游任务。
实验
实验目的
- 评估FLAT方法在不同样本数的场景下相较其他微调方法的表现
- 评估FLAT方法的稳定性
- 评估FLAT方法的计算效率
- 验证FLAT轻量化微调相较于其他轻量化微调方法具有更佳的性能,或在同样的性能下具有更佳的计算效率
- 进行消融实验,验证预训练表征降维模块、基于注意力机制的特征融合模块、任务适配器模块对实验效果的有效性
实验任务与数据集设置
采用GLUE Benchmark评估模型性能,GLUE基准测试是一组用于训练、评估和分析自然语言理解系统的测试工具,它包含九项自然语言理解任务,涉及自然语言推断、文本蕴含判断、情感分析、语义相似性估计、语法判断五种类型。由于WNLI存在类别不均衡问题,本实验排除九项任务中的 WNLI 任务。
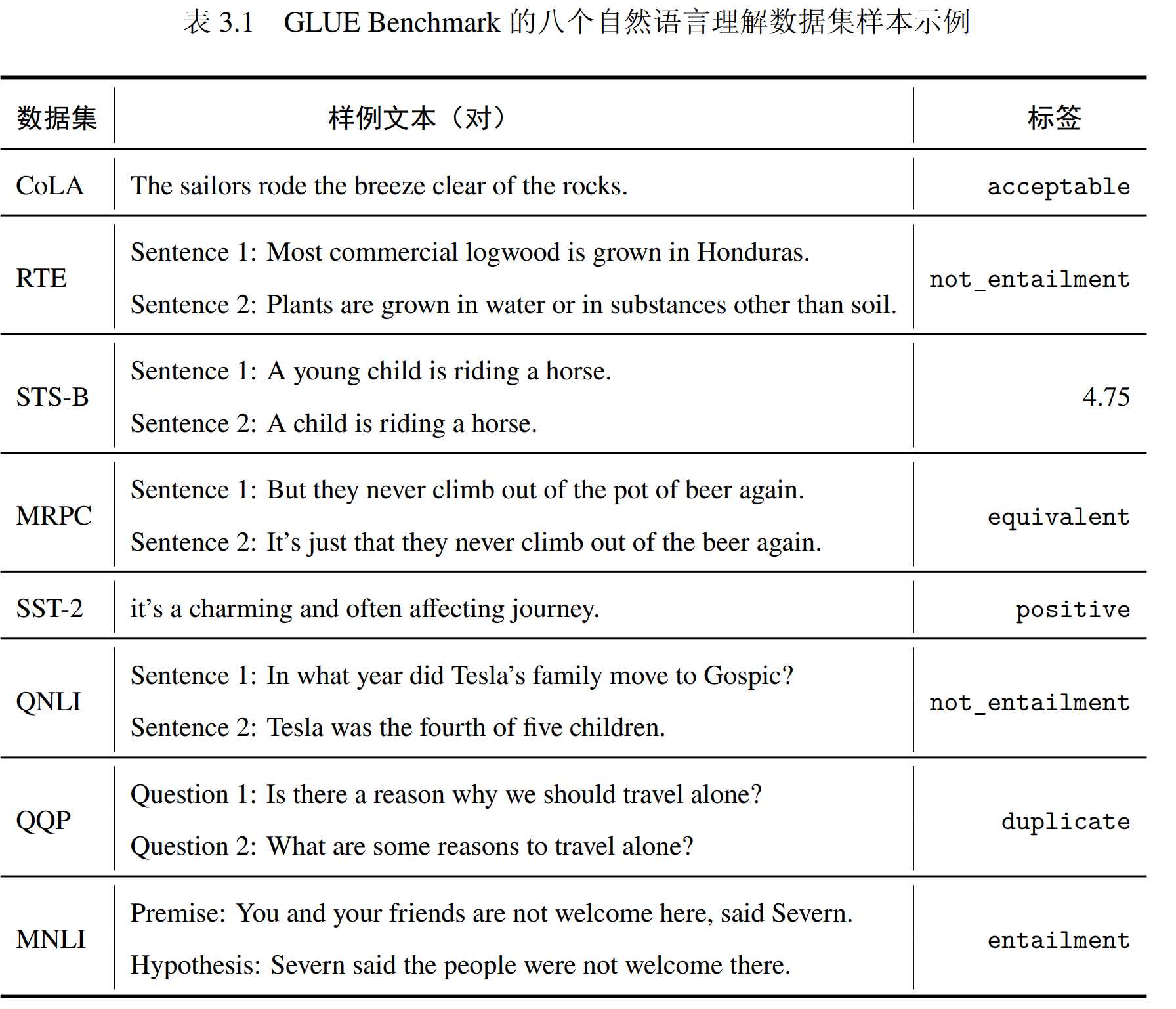
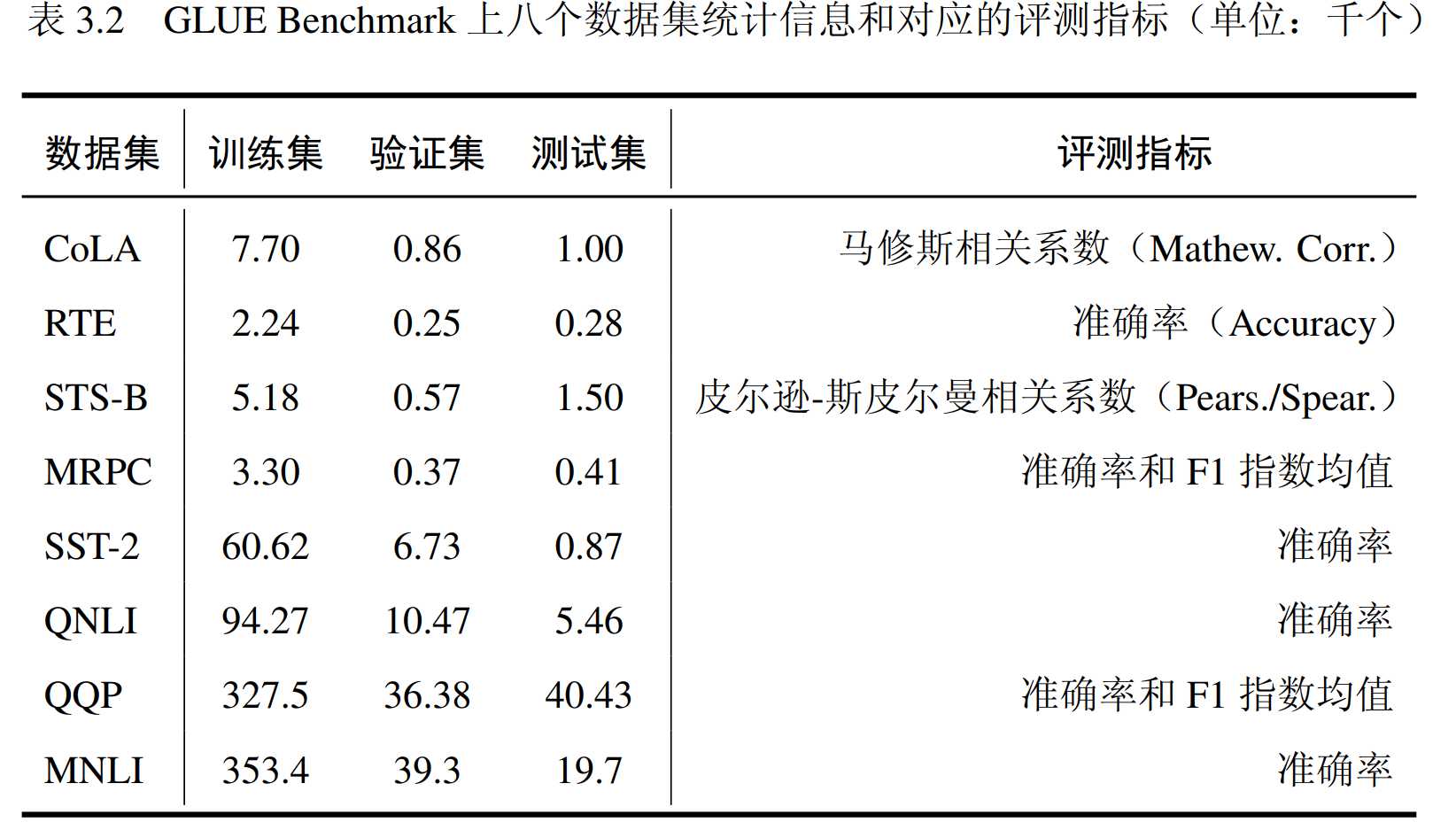
实验基于少数据样本和全数据样本两个场景对比Fine-tuning、Adapter、LORA、Prefix-tuning四种不同的微调方式在BERT-base、BERT-large、BERT-large三种模型上的微调效果、计算效率。
实验结果
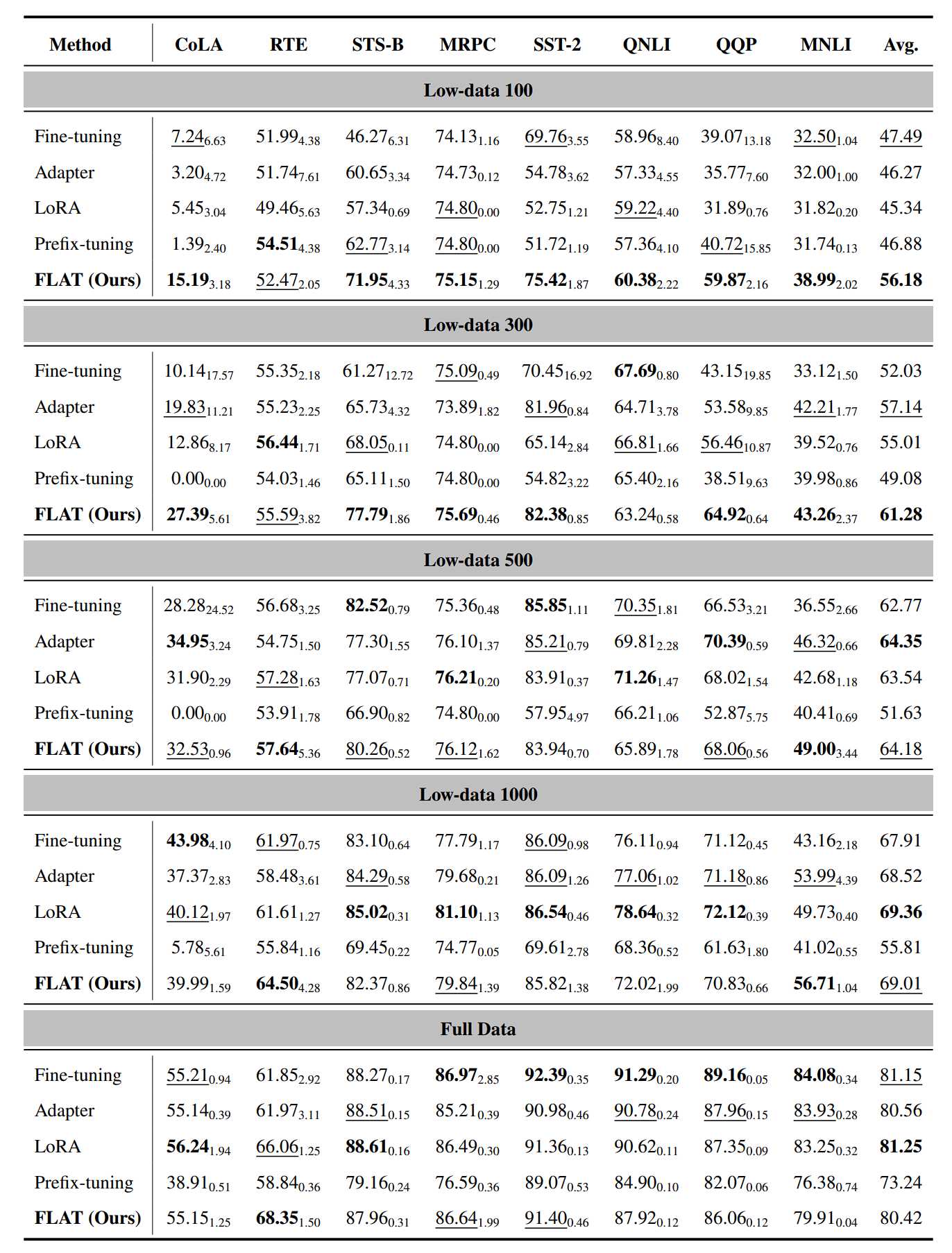
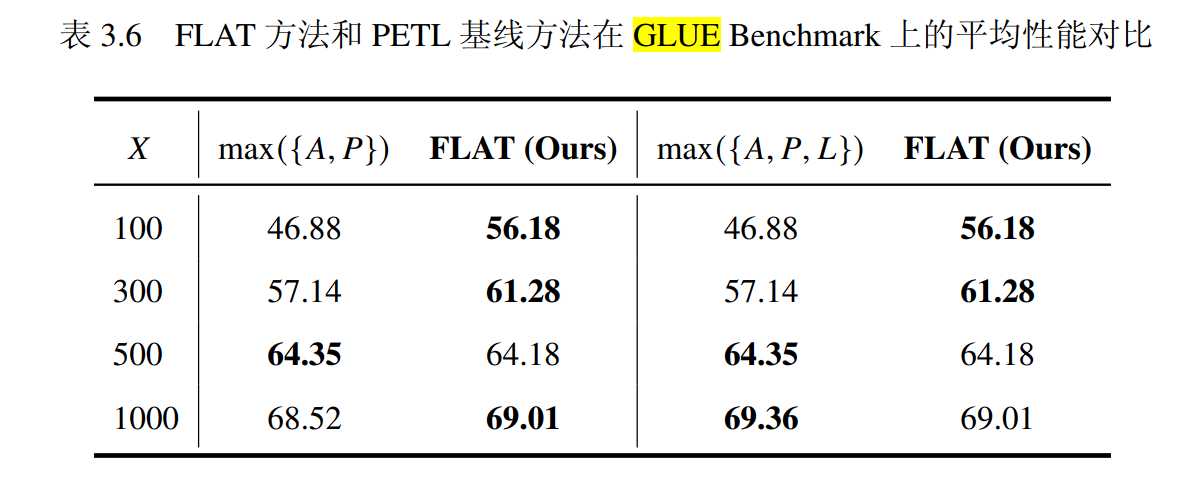
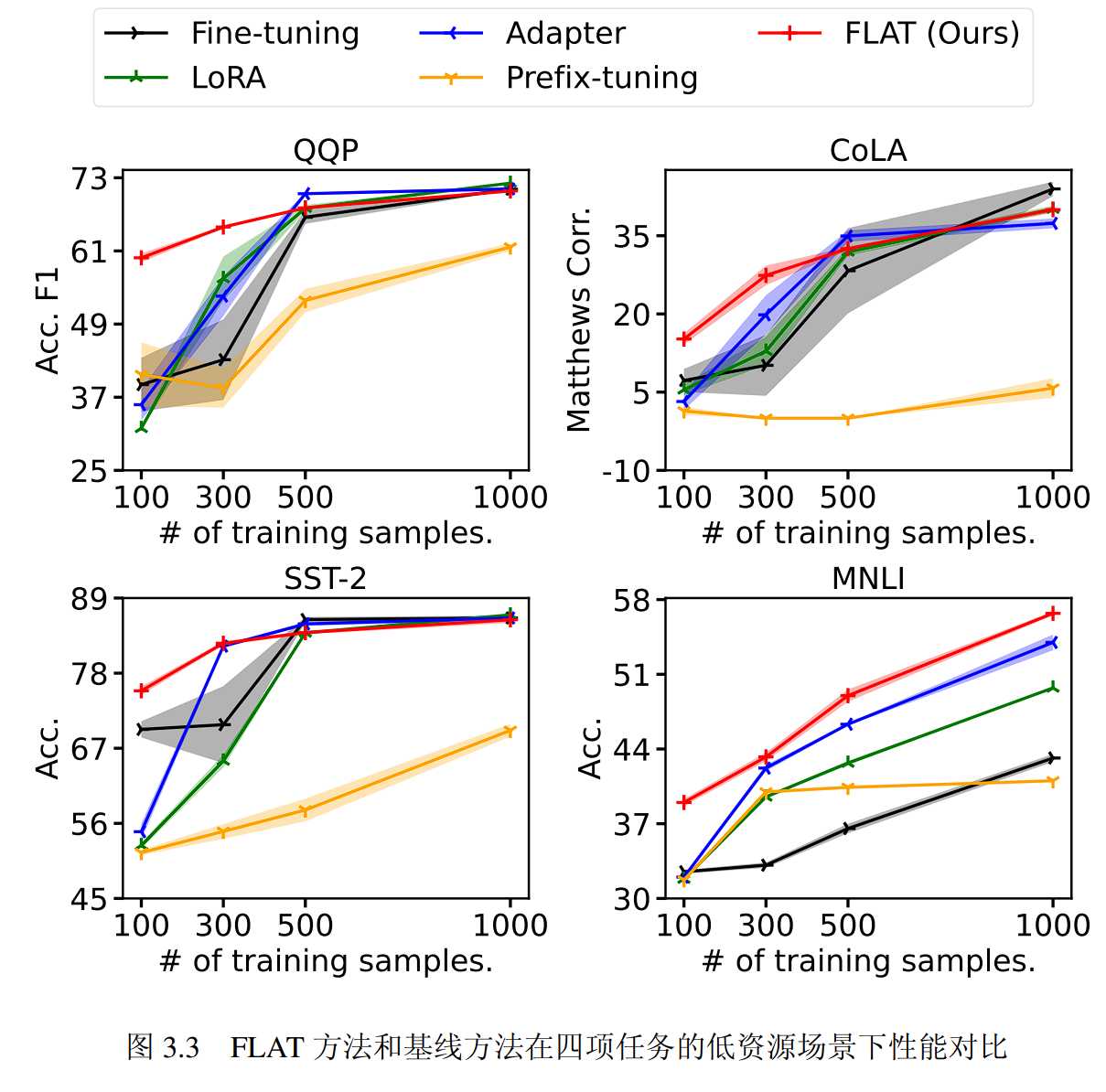
就微调性能而言,FLAT方法在低资源场景下表现优于全量微调和PETL基线方法。具体来说,在Low-data 100和Low-data 300场景下,FLAT方法在大部分任务中取得了最佳性能。此外,根据表3.6中的数据,FLAT方法在四个低资源场景中的三个上都取得了优于Adapter方法和Prefix-tuning方法的平均性能。即使与性能最佳的PETL基线方法LoRA相比,FLAT方法仍然在两个低资源场景下取得了最优的平均性能。图3.3显示,当训练数据非常有限时,FLAT方法仍然能够达到可用的性能,而同样场景下的基线方法则明显不如FLAT方法。
与此同时,实验表明在低资源场景下,一些基线方法存在训练失败的问题。Prefix-tuning 方法在 CoLA 任务的两个低资源场景下的测评结果为 0。在 MRPC 任务的 Low-data 100 和 Low-data 300 上,LoRA 方法和Prefix-tuning 方法在三次不同随机数种子的实验中都输出了不正常的相同结果。相比之下,FLAT 方法从未出现训练失败的情况,这说明 FLAT 方法相比基线方法在低资源场景下更具稳定性,且可以用在其他方法无法使用的极低资源场景。
而在富样本场景下,FLAT 方法可以取得与全量微调相当的指标,而且仅需要微调全量微调0.53%的参数。虽然性能指标分别比 LoRA方法和 Adapter 方法低 0.83 和 0.14,但是可以比他们节省两倍的内存。
当所有训练数据都可用时,FLAT 方法在八项任务中的三项中取得最优或次优的性能,并且从未取得最差性能。
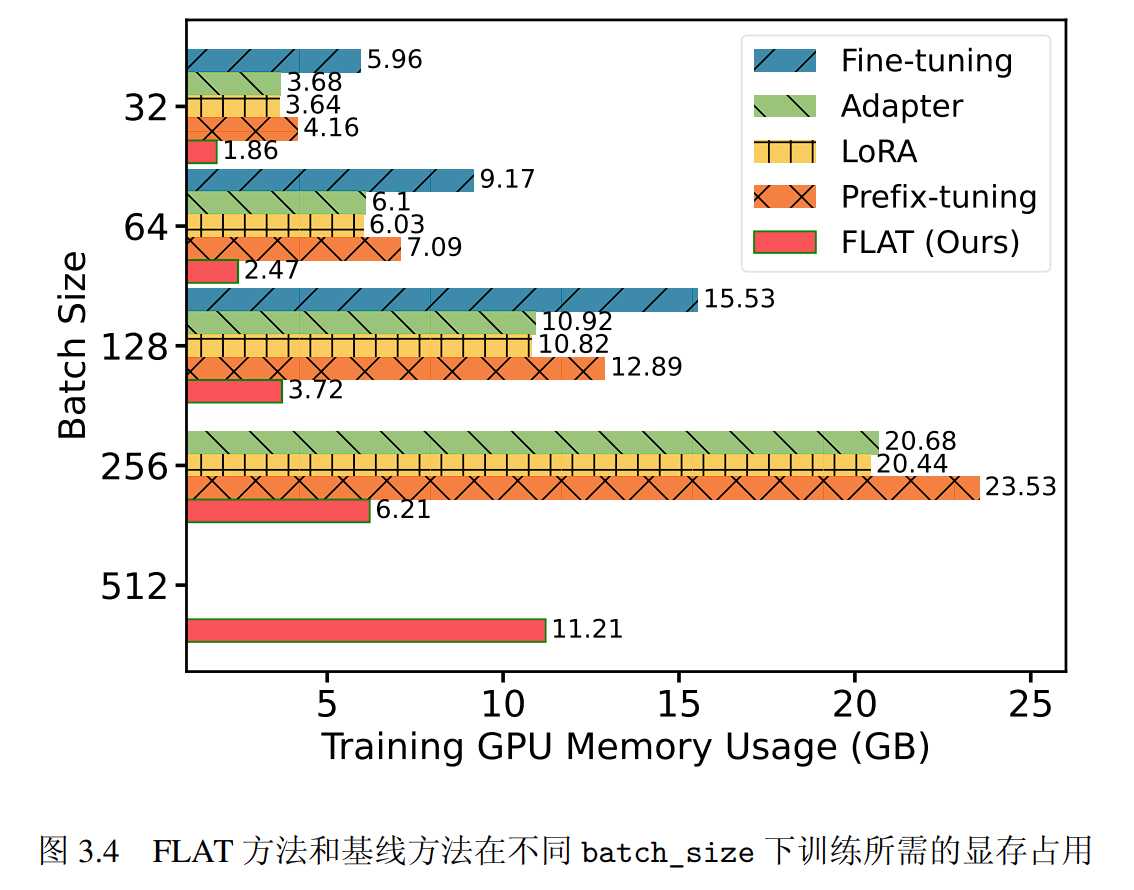
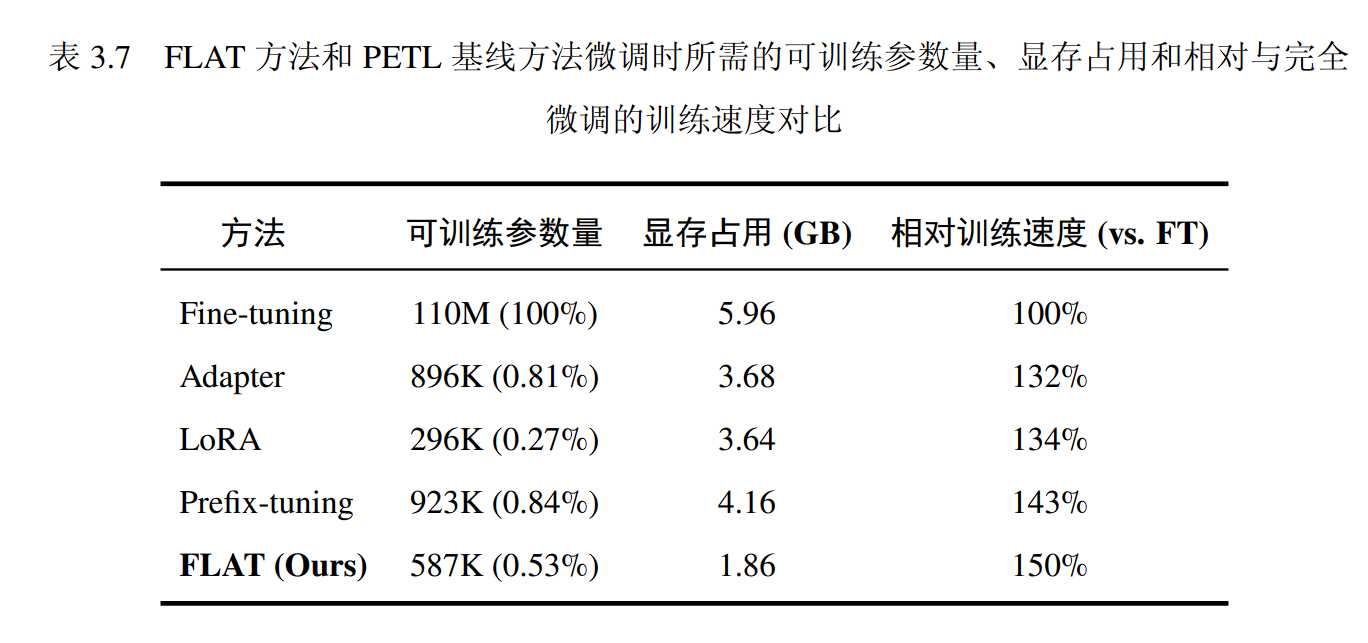
就计算效率而言,FLAT在参数效率、显存效率、训练速度均具有优势。
当设置 𝑟FLAT = 16 时,FLAT 方法能够取得与 PETL 方法相当的性能,而且参数量少于Adapter 和Prefix-tuning 方法。
当batch_size增加时,显存占用始终低于其他轻量化微调方法,当batch_size=512时,24G的GPU依然可用。
实验通过单位时间内计算的样本数度量训练速度,由于FLAT未改变预训练语言模型的内部表征,因此训练的反向传播过程绕过了庞大的预训练语言模型参数,FLAT取得了最优的训练速度。
消融实验
预训练表征降维模块
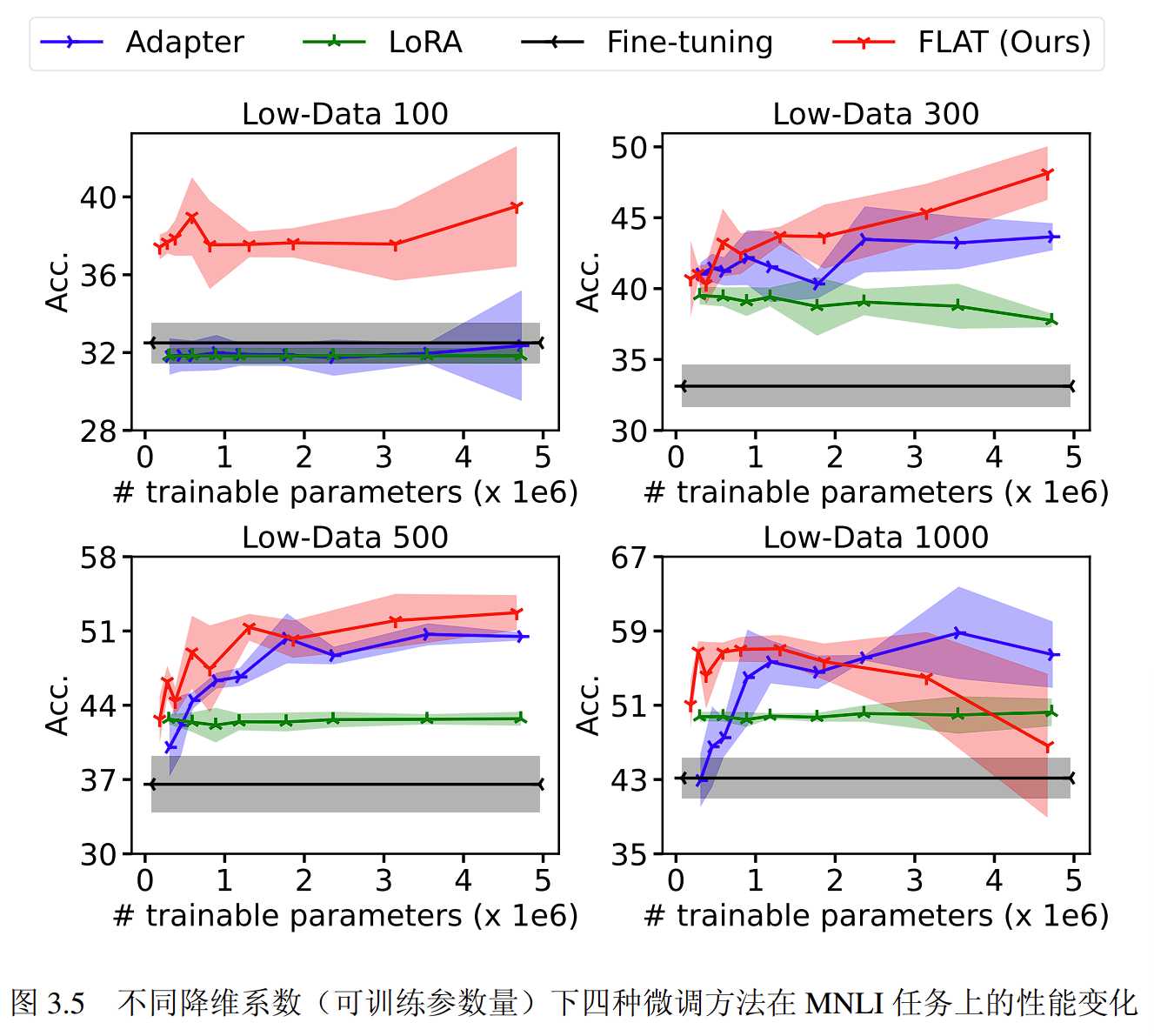
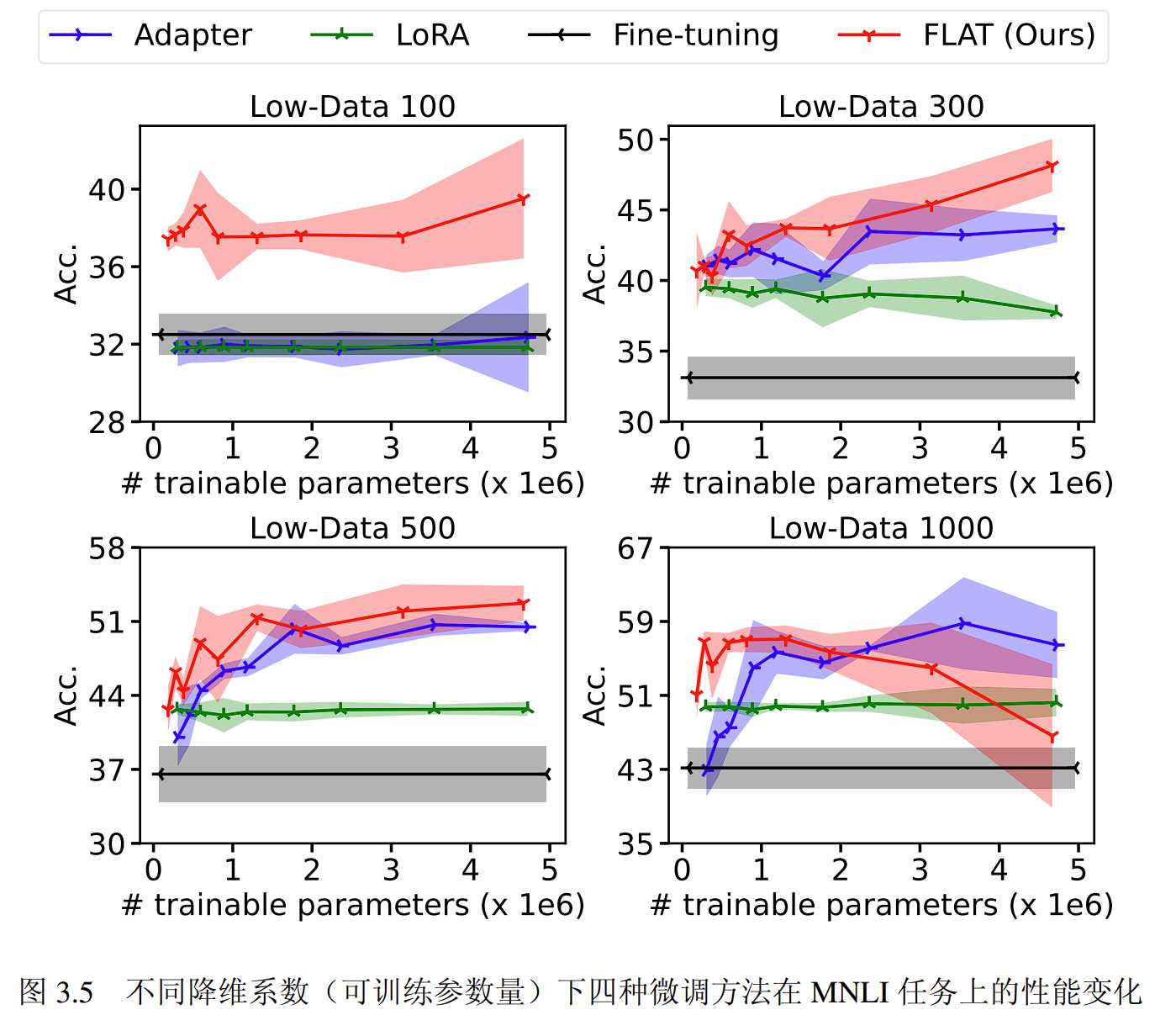
实验通过对比不同降维参数对模型的影响验证降维模块对模型架构的作用。
实验对三种方法分别使用了 9 个降维参数,分别是:𝑟FLAT, 𝑟Adapter ∈ {3, 4, 6, 8, 12, 16, 24, 32, 48},𝑟LoRA ∈{8, 16, 24, 32, 48, 64, 96, 128}。在全部的四个场景中,LoRA 方法的性能在不同的 𝑟LoRA 值下变化不大,Adapter 方法和 FLAT 方法在不同的降维系数下表现存在较大变化,例如在 Low-data 300 和 Low-data 500 场景下,两种方法的性能都随着可训练的参数增加而增强。总的来说,FLAT 方法的性能随降维参数的变化趋势与 Adapter 方法相似,并且在大多数的降维系数下都能保持性能优势。
注意力机制融合层
实验设计了三种融合策略替换 FLAT 方法中基于注意力机制的特征融合层,验证其设计的有效性。
1. 平均融合:
相当于去除融合层,将预训练语言模型所有层的表征降维后直接相加并计算均值
2. 门控融合:
其中 $G^{(ℓ)}$ 是第 ℓ 层的门控系数。
门控融合策略的融合模式适用于特定任务,该策略为每一层引入一个可训练的门控系数,并在下游任务中训练该门控系数
3. 线性融合:
其中$W \in\mathbb{R}^{\frac{d}{r} \times L}, \quad b \in \mathbb{R}^L$分别是线性层的权重矩阵和偏置向量。
该融合策略引入一个线性层为预训练语言模型不同的层计算融合系数,并且融合系数的计算基于每个 token 的表征。新引入的线性层在下游任务上训练,因此该融合策略所计算得到的融合模式既特定于任务,又特定于 token。
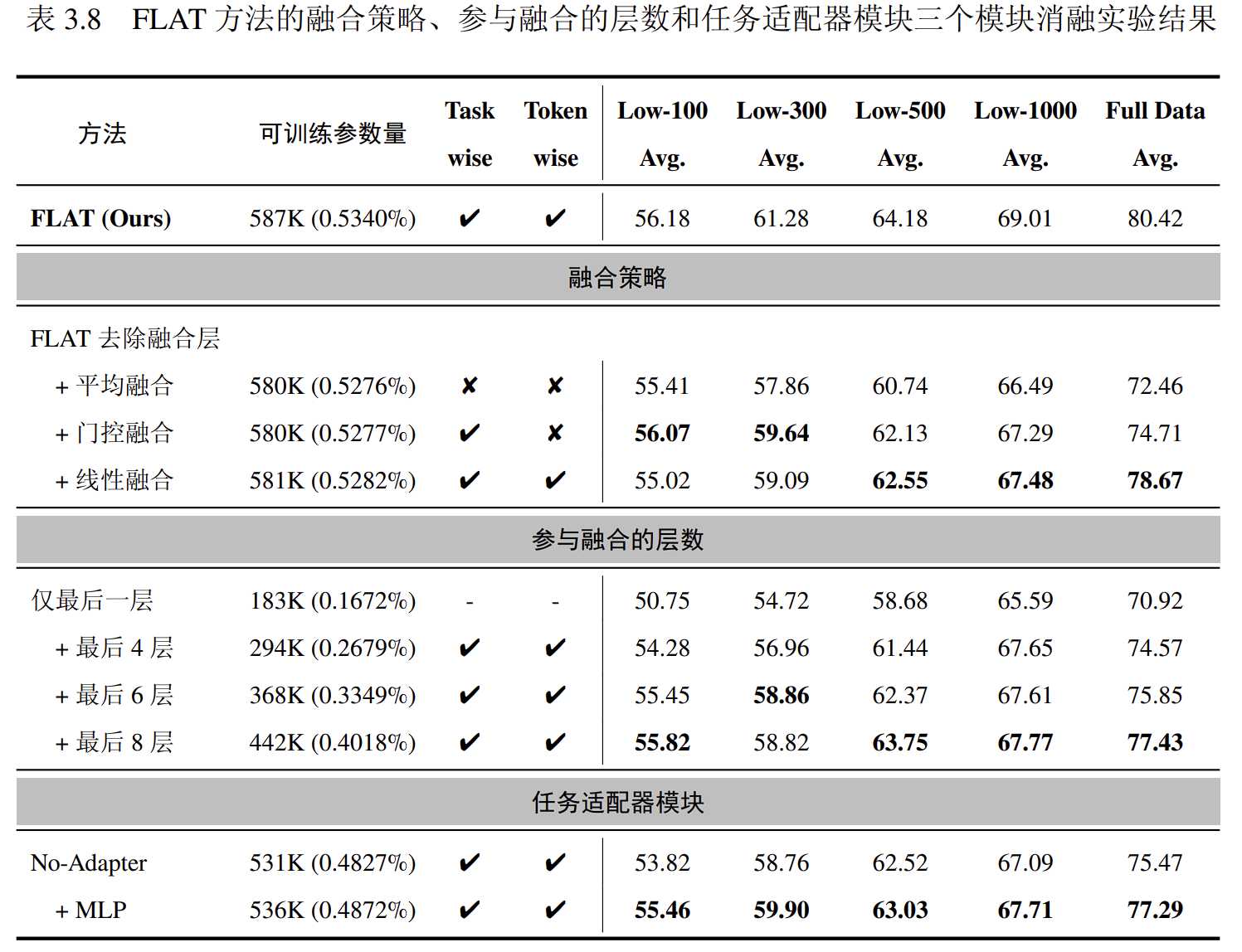
实验结果如下:
简单的平均融合方法在所有方法中表现最差,而门控融合策略的性能则比平均融合方法高0.8分。FLAT方法的token粒度融合层设计在增加少量可训练参数的情况下取得显著更高的分数,表明 token 粒度的融合层设计有效。
同时,我们探讨了预训练语言模型层数对融合层性能的影响。如下表所示,在GLUE Benchmark上的实验结果表明,仅考虑预训练语言模型的最后1层时模型表现最差,而最后4层的模型相比之下平均性能提升了3分以上。最后8层的模型表现最好,但相比原始FLAT方法性能有所降低。
任务适配器模块
为验证任务适配器模块有效性,我们分别构造去除任务适配器模块(No-Adpater)的 FLAT 模型,和将任务适配器模块替换为一个朴素的多层感知机模块(+MLP)的模型与原模型进行对比试验。
实验结果见上表 3.8 。结果表明,当去除任务适配器模块时,模型的平均性能下降了接近 5 分。当加上 MLP 模块作为任务适配器模块的替代时,模型平均性能仍然相比原始 FLAT 模型低超过 2 分。这说明任务适配器模块可以更好地将文本表征与下游任务对齐,并且 Transformer 结构在其中起到重要作用。
DK-IE
模型架构
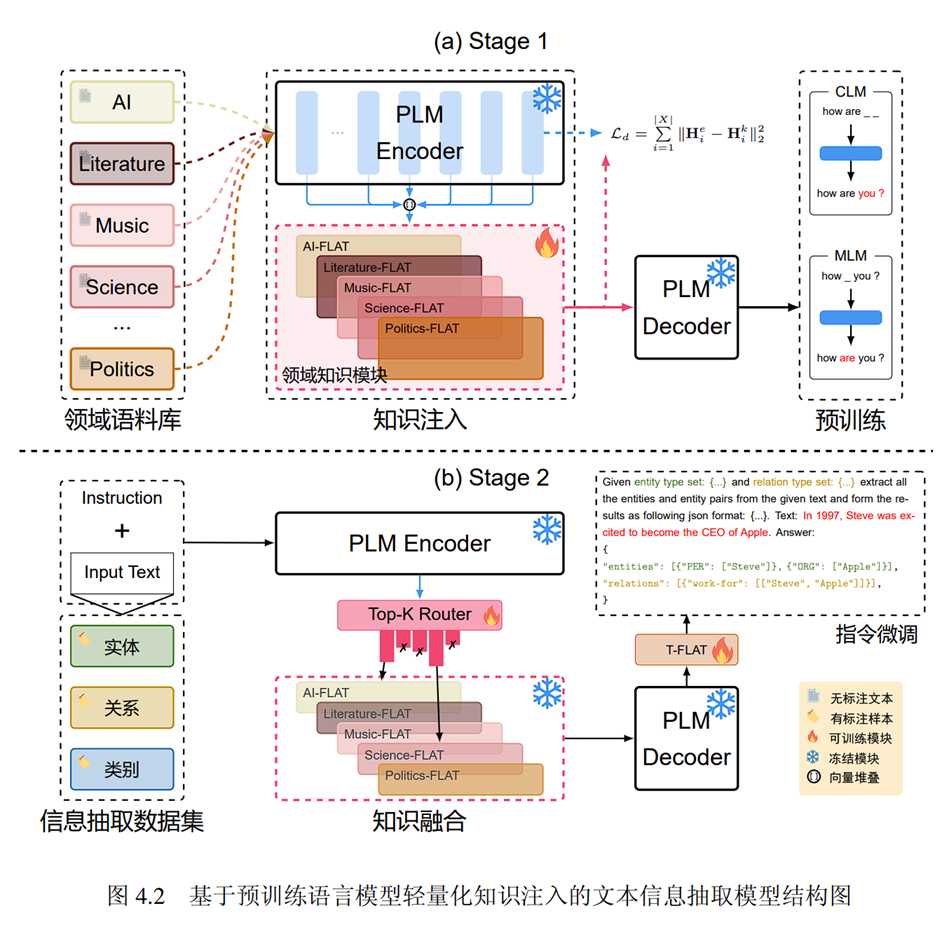
训练过程分为两个阶段:知识注入阶段和指令微调阶段
- 知识注入阶段:向CodeT5+编码器引入FLAT模块,并在多个领域的无标注语料库上进行预训练,以注入领域知识。此阶段还包括基于L2范数的知识蒸馏损失,以利用CodeT5+在预训练中学到的知识并稳定K-FLAT模块的训练。
- 指令微调阶段:在具体的信息抽取任务上进行指令微调训练。构建指令模板,将任务输出格式化为JSON代码,并利用预训练语言模型的能力进行语义目标的抽取。
知识融合:引入Top-K知识路由层,融合多个K-FLAT模块的知识,并将融合后的文本表征输入到CodeT5+的解码器。
解码器的适应性:引入基于FLAT模块的任务迁移模块T-FLAT,与Top-K路由模块共同训练,使DK-IE模型能够根据输入文本选择合适的领域知识进行文本生成。
输出格式如下

实验
实验目的
- 验证DK-IE模型性能优于其他模型
- 验证K-FLAT、T-FLAT、TOP-K模块的有效性
实验结果
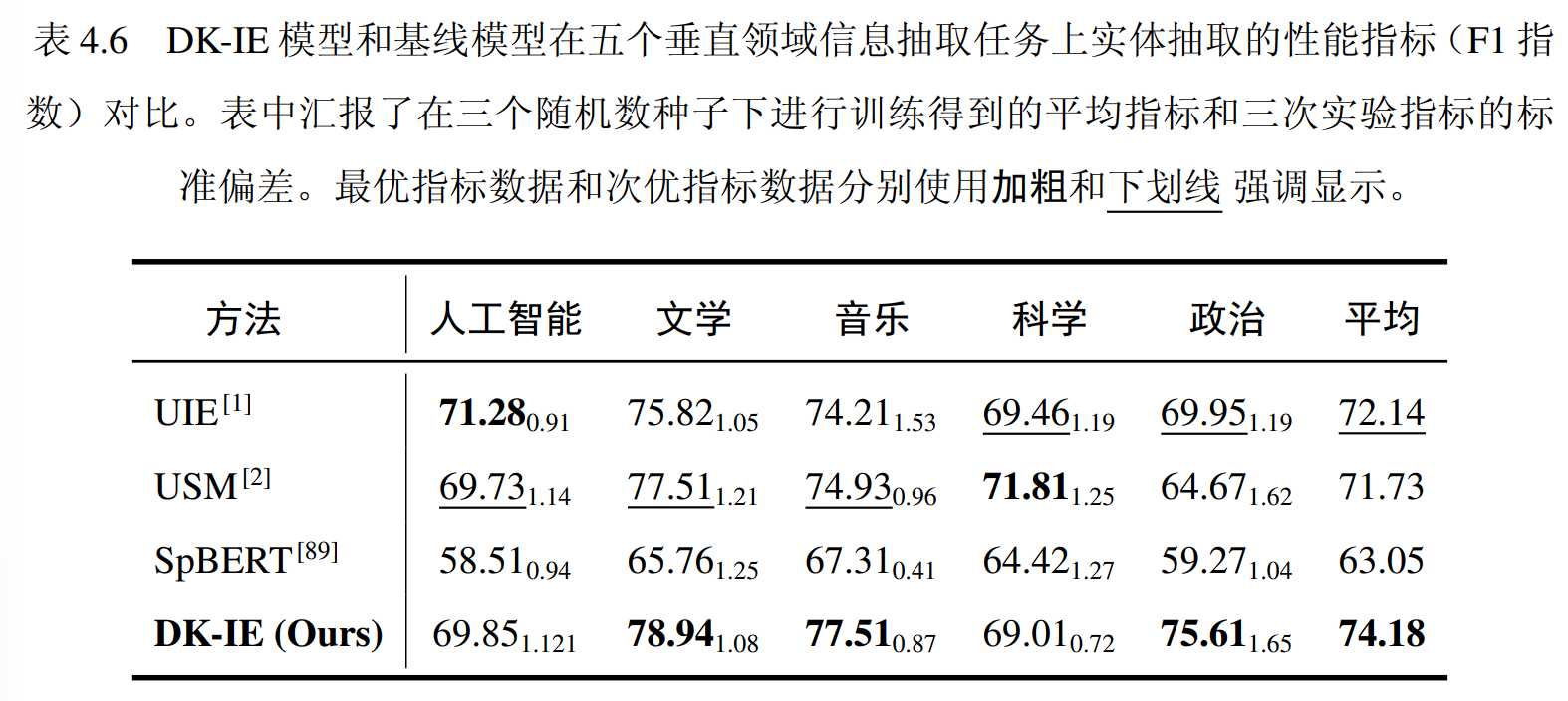
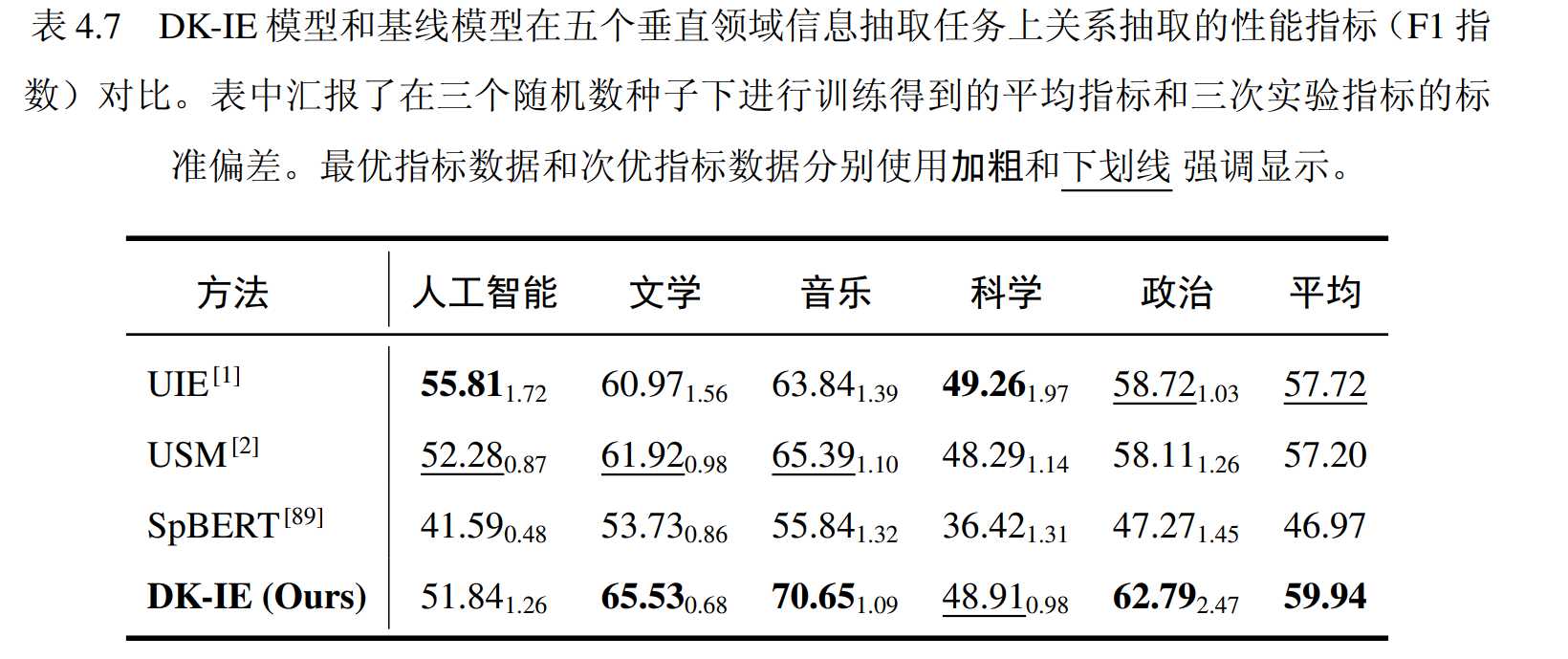
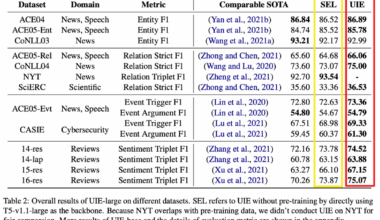
信息抽取性能如上图所示。在五个领域中,实体抽取的平均性能超过最佳基线方法超过 2 分。在音乐、政治、文学领域中,DK-IE 模型表现最优。在人工智能和科学领域,DK-IE 模型相对较差,但性能指标相差不大。总体而言,DK-IE 模型在垂直领域中的信息抽取问题上表现优异,优于三种基线模型。
文章同时探究了在具体领域的信息抽取任务上 Top-K 领域知识路由模块如何处理多个领域的 K-FLAT模块。实验记录所有领域的测试集中每个数据样本的权重 s^{(𝑘)},并在该领域的所有测试集样本中取平均,代表该领域中信息抽取任务总体的 K-FLAT 模块权重,将结果可视化为下图 4.4 。
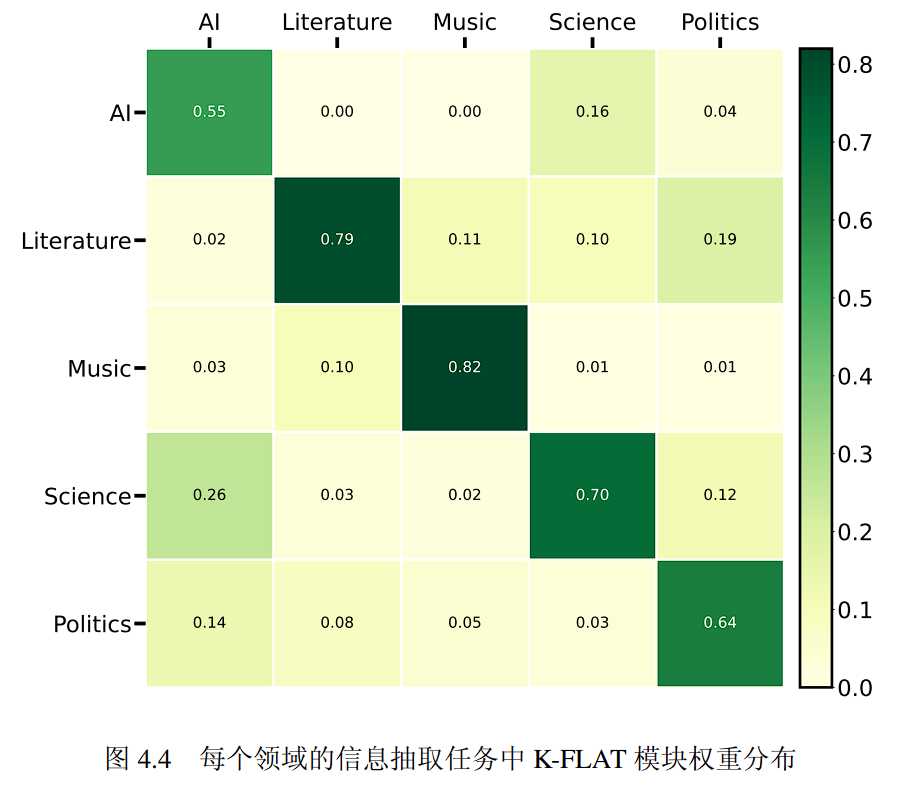
图中横轴代表信息抽取任务所属的领域,纵轴代表 K-FLAT 模块预训练的领域,图中的数据表明,模型在执行五个领域上的信息抽取任务时其领域知识路由模块分别为相对应领域的 K-FLAT 模块赋予了最高的权重。且在每个信息抽取任务上,领域知识路由模块可以为其他领域的 K-FLAT 模块赋予较小的权重,从而融合多个领域的知识为信息抽取任务服务。
消融实验
预训练K-FLAT模块
通过对比不同程度语料库的知识注入效果来评估K-FLAT模块的有效性。具体来说,首先设置不同比例的语料库,并分别进行预训练从而获得知识丰富度不同的 K-FLAT 模块,然后在不同比例的语料库上预训练K-FLAT模块,进行信息抽取任务的训练和评估。
实验结果如下图所示:
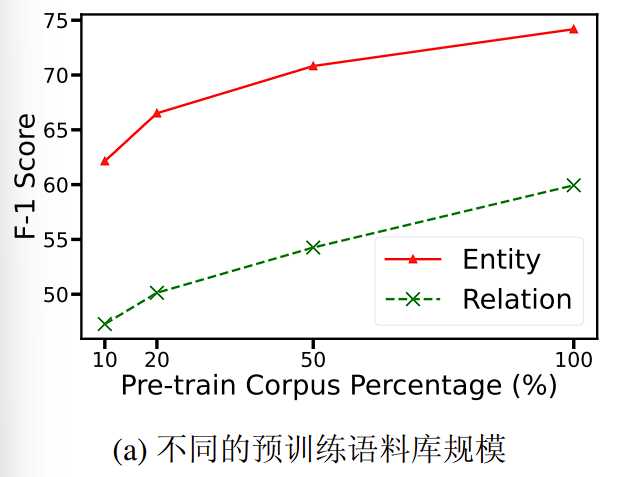
结果表明,在全部预训练数据都用于训练时,模型取得了最优的性能,在预训练数据仅有 10% 时模型性能相比 20% 预训练数据的场景降低最优严重。这说明 K-FLAT 模块的预训练过程会对后续的信息抽取任务产生较大影响,且更多的预训练数据通常会增强模型在信息抽取任务上的表现。并且,图中的数据表明在预训练数据较少时模型的性能指标随预训练数据的增加增长较快,很可能存在一个效率和性能的最佳的平衡点,在该平衡点上可以均衡训练效率和训练效果。
Top-K 领域知识路由模块
通过比较不同的TOP-K系数对模型效果的影响,探究TOP-K模块对模型的有效性。
实验设置 𝐾 = {1, 2, 4, 5} 分别在五个领域的信息抽取任务上重新进行指令微调训练,并汇报五个任务的平均性能指标。
实验效果如下图所示:
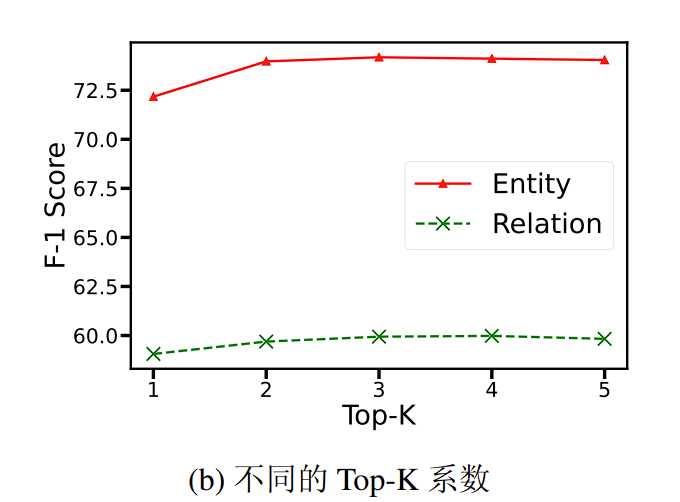
当 Top-K 系数设置为 1 时,模型性能显著下降,因为模型仅使用权重最高的 K-FLAT 模块输出作为解码器输入,没有利用其他相关领域知识。
将 Top-K 系数增加到 2,模型能够融合两个领域的知识,性能与最优 Top-K 系数(( K = 3 ))相比差距不大。
当融合更多 K-FLAT 模块(( K = {4, 5} ))时,由于引入不相关领域知识的噪音,模型性能略有下降。
DK-IE 模型通过领域知识路由模块动态计算所有 K-FLAT 模块的权重,实现逐样本的知识融合。对于大多数样本,融合两个领域的知识已足够提升信息抽取性能。在五个不同的 Top-K 设置下,模型性能表现整体稳定,表明模型对 Top-K 系数的设置具有较强的鲁棒性。
Top-K 路由层能够根据样本信息选择和加权融合领域知识模块,有效避免噪音影响,证明了 Top-K 领域知识路由模块的有效性。
T-FLAT任务迁移模块
为验证任务迁移模块的有效性,我们将 T-FLAT 模块分别替换为一层朴素的线性层(Linear)和两层的多层感知机(MLP)模块,分别重新进行指令微调训练,并对比该设置下模型在五个信息抽取任务上的平均指标。
实验结果如下所示:
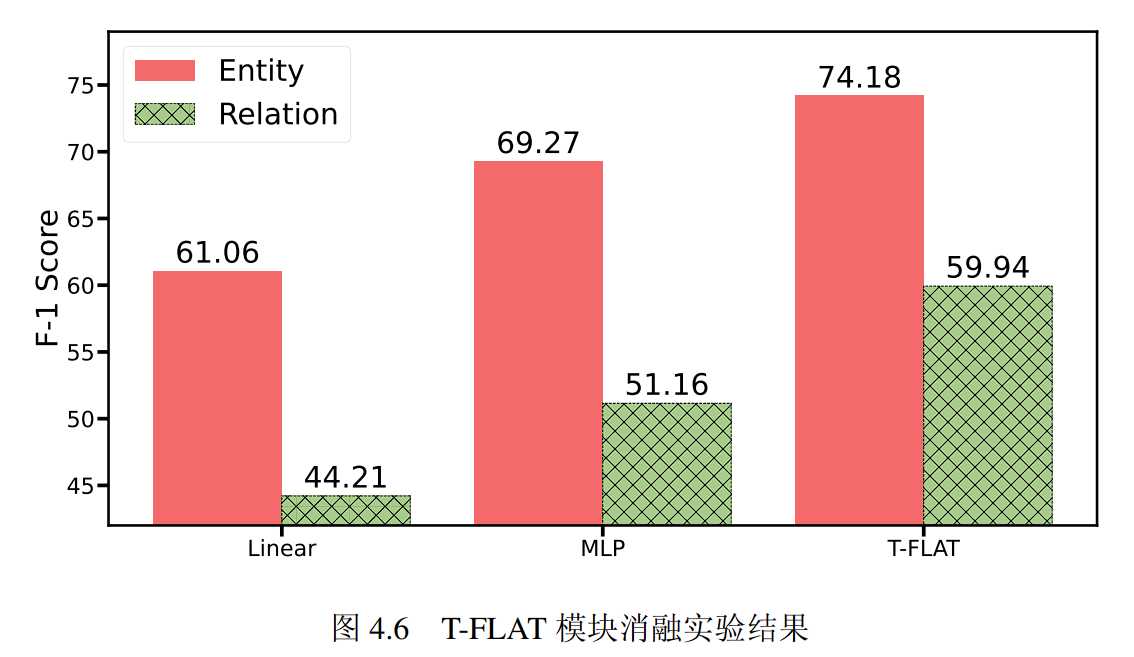
实验结果表明,使用两种朴素模块替换 T-FLAT 模块后模型的性能表现均有下降,且朴素线性层(Linear)模型性能下降显著。这表明仅在下游任务上微调朴素的神经网络模块难以建模复杂的结构化文本生成任务,T-FLAT 模块由于采用了高效的 FLAT 模型结构可以显式地融合预训练语言模型解码器部分的语言知识,并经过低秩的Transformer 模块进行上下文计算则可以高效地将模型迁移到信息抽取任务。
原作者:南京航空航天大学 朱文强 2024