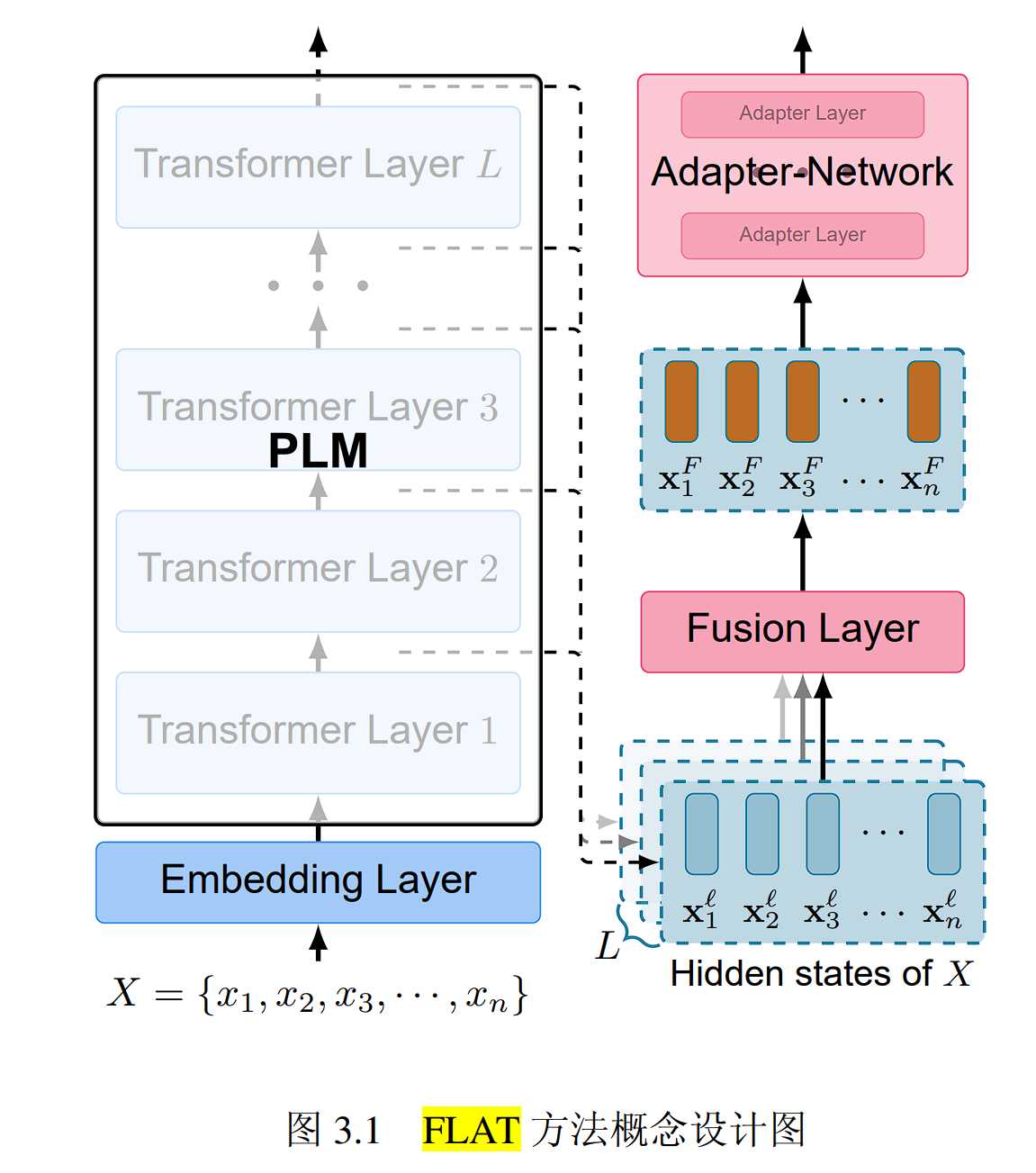
简介
作者认为:当前的信息提取方法都是针对特定任务的,需要对特定的任务单独进行训练,这导致了各方法间模型孤立,抽取的方法架构也无法复用,而且需要针对不同的IE任务寻找专门的知识源。
这导致以下几个问题:
1. 为大量IE任务/设置/场景开发专用架构非常复杂。
2. 学习孤立的模型严重限制了相关任务和设置之间的知识共享
3. 构建针对不同IE任务的数据集和知识源既昂贵又耗时
作者基于此将不同IE任务统一建模为“文本到结构”的转换任务,将所有的IE任务分解为定位和关联两个元子任务。具体来说,定位就是找到与预定义语义类型(semantic types)相关的文本段(span),关联则是与预定义抽取模式(pre-defined schemas)相关的语义角色文本(semantic roles)对进行连接。
为了实现这一任务,作者设计了结构化抽取语言(SEL,Structured Extraction Language)来统一编码异构提取结构,即编码实体、关系、事件统一表示。同时构建了一种结构化模式提示器(SSI,Structural Schema Instructor),一个基于schema的prompt机制,用于控制不同的生成需求。
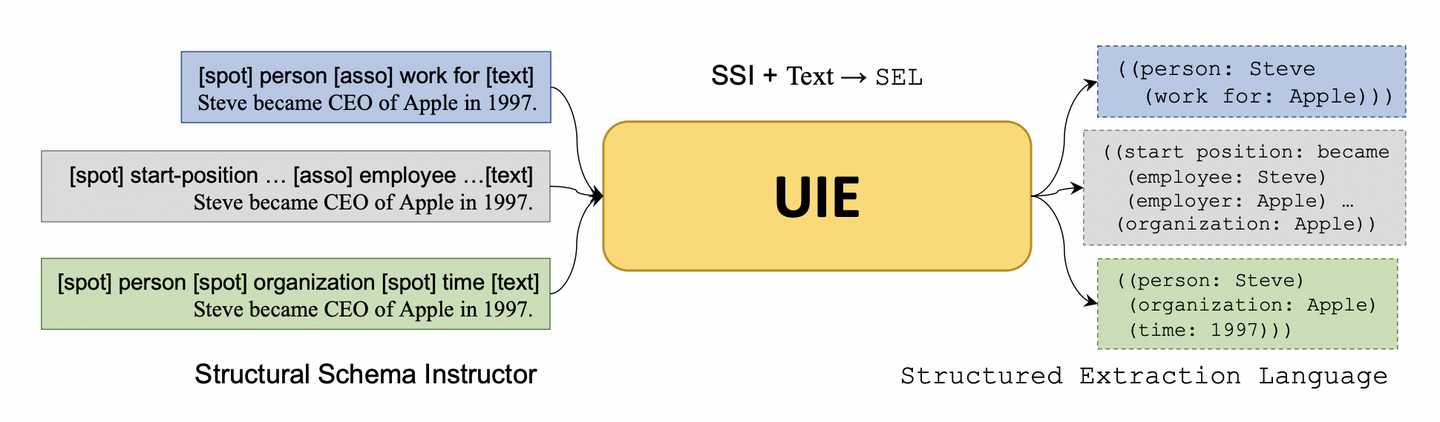
上图展示了UIE的整体框架,整体架构就是:SSI + Text -> SEL
简单概括就是:SSI将指示特定任务的schema插入promot,SEL将不同任务的抽取结果统一用结构化语言表示。
作者通过设计这一架构尝试解决如下问题:
1. 开发一种通用信息抽取网络,将不同信息抽取任务统一建模为文本段到结构的任务
2. 从不同的知识来源统一学习通用的信息抽取能力,根据promot自适应不同的抽取任务生成目标结构
模型架构
SEL(Structured Extraction Language)

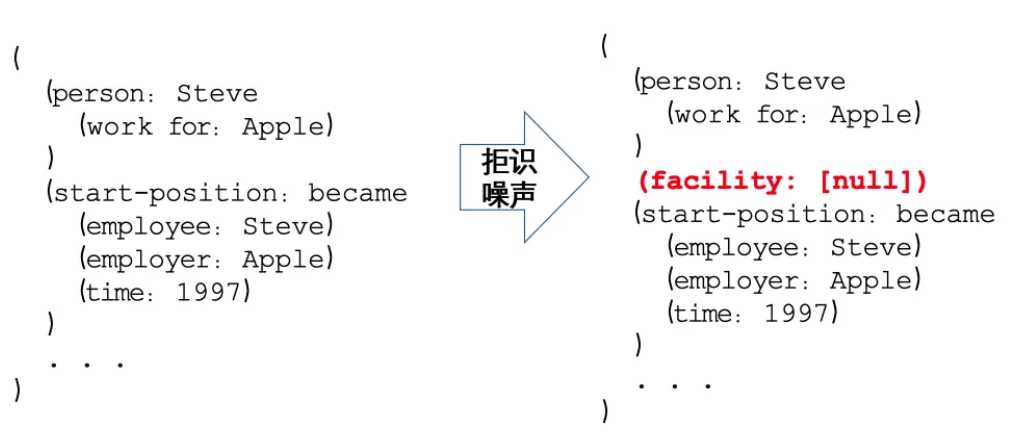
假设输入的句子为:”Steve became CEO of Apple in 1997.”,有三个实体,人: Steve、公司:Apple、时间: 1997. 下图则为结构化抽取语言对于抽取结构的表示。如蓝色代表的是关系抽取,红色代表的事件抽取,最后则为实体的抽取。红色部分的触发词是became。雇主是Apple,雇员是Steve,时间在1997年。
可以看出SEL的优点有:
1. 对不同的IE结构进行统一编码,因此可以将不同的IE任务建模为相同的text-to-structure生成过程;
2. 有效地将一个句子的所有提取结果表示为同一结构,能够自然地进行联合提取;
3. 生成的结构化语句可以非常方便的使用程序解码,便于任务的迁移。
SSI(Structural Schema Instructor)
由于不同的IE任务有不同的模式,我们需要用一个引导器指示模型一个句子里哪些信息是抽取任务需要的。
具体而言,对应于发现-关联结构,结构模式指导器包含三种类型的令牌段:1)SPOTNAME:特定信息提取任务中的目标发现名称,例如在NER任务中的“person”;2)ASSONAME:目标关联名称,例如在关系提取任务中的“work for”;3)特殊符号([spot],[asso],[text]),它们被添加在每个SPOTNAME,ASSONAME和输入文本序列之前。SSI中的所有令牌都被连接起来,并放在原始文本序列之前。如图3所示,UIE的整个输入形式为:
s ⊕ x = [s1, s2, …, s|s|, x1, x2, …, x|x|]
=[[spot], …[spot]…, [asso], …, [asso]…, [text], x1, x2, …, x|x|]
例如,SSI “[spot] person [spot] company [asso] work for [text]” 表示从句子中提取关系模式“the person works for the company”的记录。
y = UIE(s ⊕ x) 给定SSI s,UIE首先对文本x进行编码,然后使用编码器-解码器风格的架构生成线性化的SEL中的目标记录y。
基于模式的提示可以:
1. 有效地指导UIE的SEL生成,以便将通用IE能力转移到新的IE任务;
2. 适应性地控制要发现、要关联和要生成的内容,以便跨不同标签和任务更好地共享语义知识。
但是与此同时也有潜在缺点:
如果抽取的实体类型、关系类型非常多的话,输入文本长度可能会非常长,效率?
UIE
使用Transformer编解码器架构,本文使用T5-v1.1-base和T5-v1.1-large给定原始序列文本x和模式指导器s,UIE首先通过编码器计算每个token的隐藏表征H
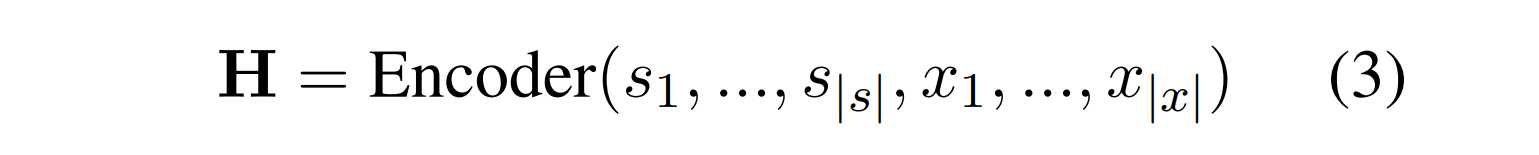
然后UIE按照自回归的方式,将输入文本解码成一个线性化的SEL(结构化提取语言)
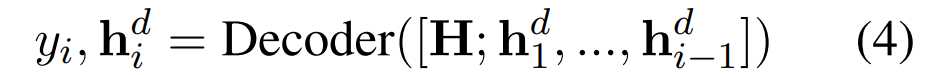
在解码的第i步中,模型将第i步之前的隐藏态输入模型进行解码。当输出<eos>时完成预测,然后将预测的SEL表达式转换为提取的信息记录。
与传统的标签视为特定符号的信息提取(IE)研究不同,我们将标签视为自然语言标记,这样有如下好处:
可以获取标签本身的语义信息,共享常见的标签-文本关联,在相近的信息抽取任务中共享知识。
如需要选取表示地点类型的实体,在不同的抽取任务中,可能有的抽取用location表示地点类型,而有的将place表示为地点类型,使用我们的模型可以将这两种不同的词语识别成近似的抽取模式。
同样的,对于victim标签,不同类型的事件都可能涉及到victim。因为无论是交通事故、自然灾害还是犯罪事件,受害者都是一个共同的标签。我们的模型可以在不同的事件抽取任务中共享victim的抽取模式。
预训练
UIE需要将输入文本进行编码,然后将编码后的文本映射到不同类型的信息抽取任务所需的目标结构(如标签、关系、事件等),最后,UIE使用解码器来生成有效的结构。
由于生成任务的文本是不可控的,我们定义损失函数让模型逐渐学会生成符合文章定义的结构并输出正确的结果。
因此预训练任务需要进行如下学习:
- 学习文本映射到结构的能力
- 学习结构化语句生成的能力
- 学习文本语义理解的能力
准备以下三个数据集:
D_{pair}:这是指文本-结构并行数据,其中每个实例由一对平行元素组成:一个标记序列(表示为“x”)和一个结构化记录(表示为“y”)。我们通过将Wikidata与英文维基百科对齐来收集大规模的文本-结构并行数据对。D_{pair}用于预训练UIE的文本到结构的转换能力。
D_{record}:这是结构数据集,其中每个实例都是一个结构化记录(表示为“y”)。我们从ConceptNet和Wikidata中收集了结构化记录。D_{record}用于预训练UIE的结构解码能力。
D_{text}:这是非结构化文本数据集,我们使用英文维基百科中的所有纯文本。D_{text}用于预训练UIE的语义编码能力。
文本映射到结构
使用Dpair = {(x, y)}对UIE进行预训练。由于只用正架构来训练UIE,它只会简单地记住预训练数据中的三元组,而学习不到一般的映射能力。因此我们抽样负spot类型ss-和负关联集sa-,然后与正样本对S+一起输入模型训练。
s_{meta}=s_+∪s_{s-}∪s_{a-}
例如,在记录“((person: Steve (work for: Apple)))”中,person和work for是正spot,我们抽取vehicle和located in作为负spot来构建s_{meta}。最终,文本到结构预训练的目标是:
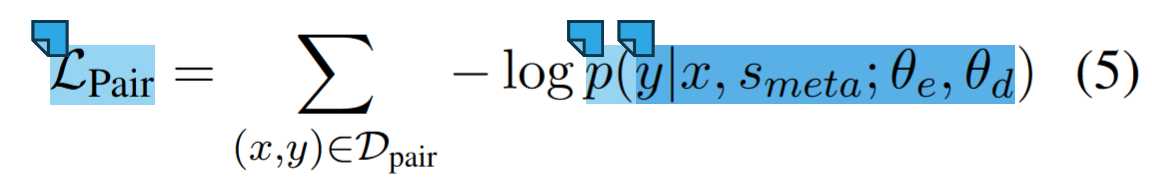
其中θ_e和θ_d分别是编码器和解码器的参数。
这个损失函数含义是:最小化预测结构 y 与真实结构之间的负对数似然,使加入混淆后的结果与真实结果尽可能接近
结构化语句生成
使用D_{record}对UIE进行预训练。我们将UIE解码器预训练为一个结构化语言模型,其中D_{record}中的每个记录都是SEL的表达式:
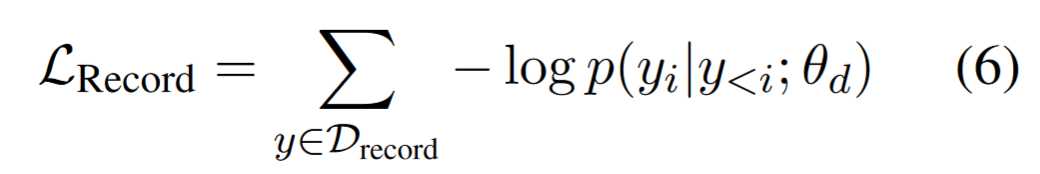
这里的p(y_i | y_{<i}; \theta_d)是模型预测的结构 y_i 在给定之前的结构 y_{<i} 和解码器参数 \theta_d 的条件下的概率。
这个损失函数含义是:最小化概率似然,以便模型的下一个字符输出尽可能匹配符合结构定义和模式的有效结构。
理解语义信息
使用了掩码语言模型任务改进UIE的语义理解能力,使用数据集Dtext进行训练。具体来说,我们在预训练阶段抽取一些原文本并替换为[mask],然后训练模型从损坏的原文本预测原来的文本段的能力:
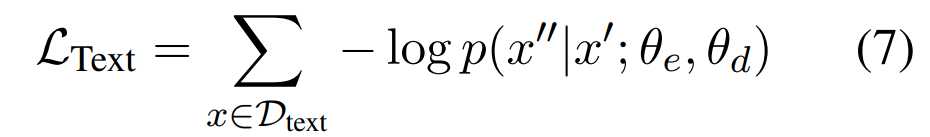
其中 ( x’ ) 是损坏的源文本(token),( x’’ ) 是损坏的目标文本段(span)。这种预训练可以有效地缓解文本语义的灾难性遗忘,特别是在SPOTNAME和ASSONAME的这类标签语义。
最终预训练标准
使用T5-v1.1-base和T5-v1.1-large初始化UIE-base和UIE-large,结合上面三项子任务:
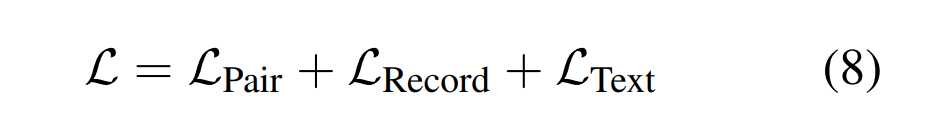
我们将所有预训练数据统一表示为三元组。对于Dtext数据集的文本数据(x),我们构建三元组(None,x^’,x^”),x’是损坏的token,x’’是损坏的span,对于Dpair中的文本-记录数据(x, y),我们通过为每对文本-记录对采样元模式s来构建(s,x,y)。对于Drecord中的记录数据y,我们将(None, None,y)作为输入三元组。我们随机将不同任务的实例打包在一个批次中统一进行训练,锻炼模型通用抽取能力。
按需微调
快速的Finetune使UIE适应不同设置下的不同 IE 任务
对于具体的任务,用标记的具体任务数据集对UIE模型进行微调。如给定一个标记的语料库Dtask = {(s, x, y)},我们使用Teacher-forcing交叉熵损失对UIE模型进行微调
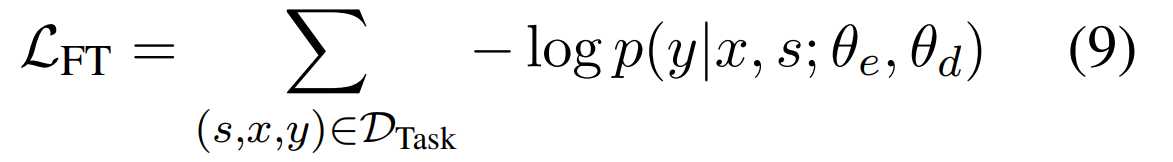
为了解决自回归Teacher-forcing的暴露偏差问题,增加了拒识噪声注入的模型微调机制:随机采样SEL中不存在的SpotName类别和AssoName类别添加到结果中并让模型学习哪些是错误的生成,即:(SPOTNAME, [NULL]) 和 (ASSONAME, [NULL]),强化模型拒绝生成错误结果的能力,如下图所示:
暴露偏差(Exposure Bias)是自然语言处理(NLP)中的一个问题,特别是在文本生成任务中。它指的是模型在训练和推断(测试)阶段使用的输入不一致导致的问题。在训练阶段,模型每次生成下一个词时都会使用真实样本(Ground Truth)作为输入,但在推断阶段,模型则使用自己在上一个时间步生成的输出作为下一个输入。这种不一致可能导致模型在实际应用中性能下降,因为它没有学会如何处理自己生成的可能错误的序列。
实验
实验目的:
- 评估UIE的通用信息抽取性能
- 评估UIE的跨任务迁移能力
- 检测SSI标签对模型的作用
- 验证拒识噪声注入的模型微调机制能否缓解暴露偏差问题
实验设置
- 数据集:
ACE04,CoNLL03,CoNLL04,NYT,CASIE,SemEval-14,SemEval-15,SemEval-16
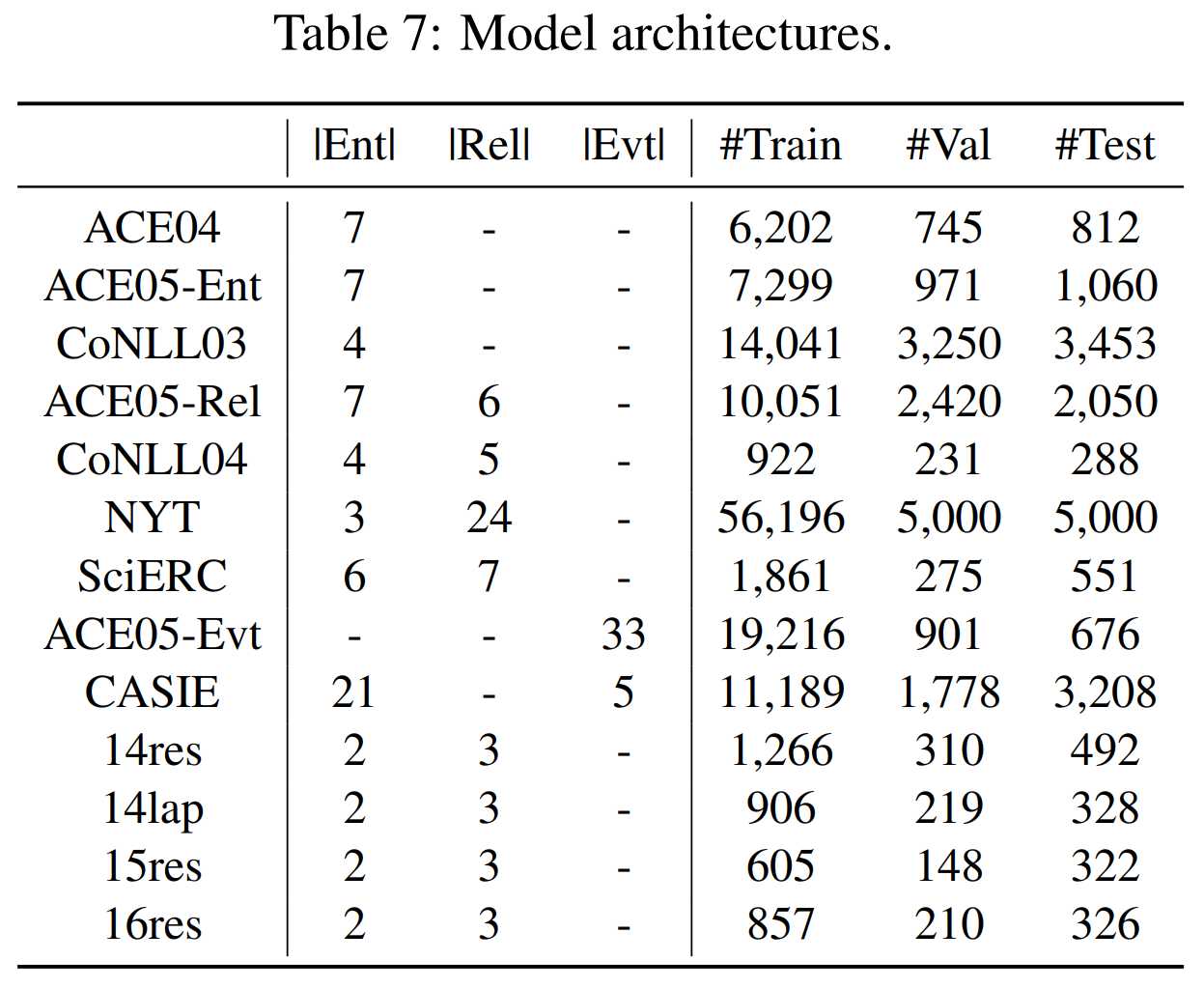
- 测试指标
评估十三个数据集在七大领域四类抽取任务的F1性能指标
实验结果
全监督实验
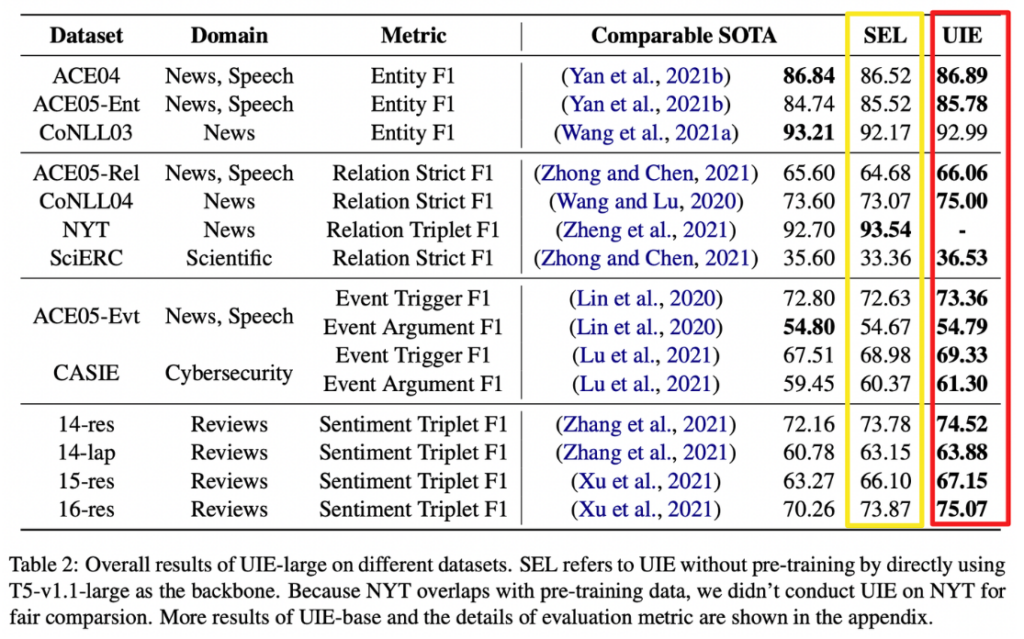
即使没有预训练,直接将T5模型作为SEL的后端,模型在几乎所有数据集和任务上都达到了最先进的性能。这表明将信息抽取任务转换为文本到结构的映射这一思路是有效的。
预训练后,模型在大多数数据集上实现了最先进的性能,在平均F1分数上提高了1.42%。这表明预训练后模型对所有信息抽取的综合能力得到了增强,具有更好的跨任务迁移能力。
少样本实验
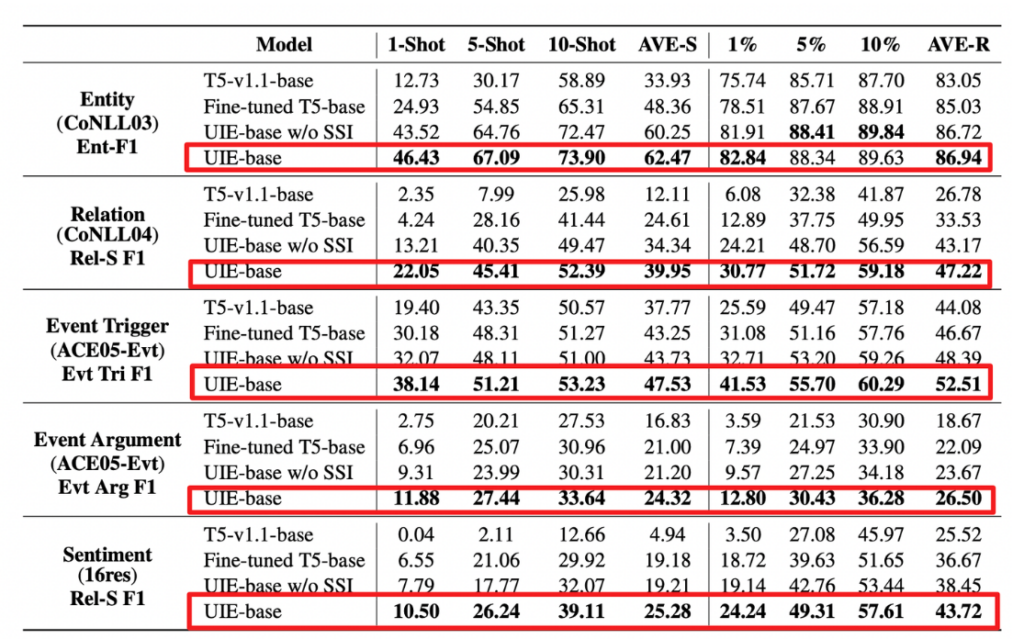
对于few-shot实验,我们从训练集中为每个实体/关系/事件/情感类型抽样了1/5/10个句子,使用不同的样本实验十次去平均。
实验结果显示少样本状态下UIE的模型性能显著好于其他模型,这表明模型理解了深层次的文本到结构转换的能力,而且当去除SSI标识的情况下,模型性能出现了大幅下降,这表明SSI在指导UIE抽取模式的有效性。
拒识噪声注入消融实验
为验证拒识噪声注入的有效性,作者将拒识噪声去除并进行对比,实验结果如下所示:

结果显示,去除了拒识噪声模块后,实验效果出现了显著的劣化,这是因为模型自身生成的错误标签对后续抽取工作产生了负面影响,导致大量错误的提取结果。这证明了拒识噪声模块的有效性。
P-R-F
当我们谈论模型性能时,P值(P-value),R方(R-squared)和F值(F-statistic)是两个常见的统计指标。
P值(P-value):P值是一个数值,通过统计检验计算得出,描述了在零假设成立的情况下,您观察到的一组数据出现的可能性有多大。具体来说:
P值告诉您,如果零假设为真,您的数据中出现您计算的检验统计量(test statistic)或更极端的情况的概率。
P值越小,您越有可能拒绝零假设。
例如,如果P值为0.05,这意味着如果零假设成立,您有5%的机会观察到至少与您发现的检验统计量一样极端的情况。
用途:
P值用于假设检验,帮助决定是否拒绝零假设。
较小的P值意味着更强的支持备择假设。
R方(R-squared):
R方是决定系数,用于衡量回归模型对因变量变化的解释能力。
其取值范围在0到1之间,越接近1表示模型能解释更多的变异。
例如,R方为0.6表示模型能解释因变量60%的变化。
但是,R方并不是唯一的评价指标,还需要综合考虑其他因素。
F值(F-statistic):
F值是方差分析量,用于整体检验回归模型是否有意义。
如果模型通过F检验(p < 0.05),说明模型有意义,至少有一个自变量对因变量产生影响。
如果模型未通过F检验(p > 0.05),说明模型构建无意义,自变量不会对因变量产生影响。