简介
作者认为:当前的信息提取方法都是针对特定任务的,需要对特定的任务单独进行训练,这导致了各方法间模型孤立,抽取的方法架构也无法复用,而且需要针对不同的IE任务寻找专门的知识源,因此需要提出一种通用的信息抽取架构。
而Lu et al. (2022)提出的UIE方法以扁平化的模式和文本作为输入,并以一个模型直接生成多样化的目标信息结构,但是该模型有如下问题:
- 由于序列到序列模型的黑盒特性,信息片段与模式标签之间的关联都是隐式确定且难以解释
- 任务迁移模式难以解释,无法保证迁移模式的鲁棒性和有效性
作者基于此,将所有IE任务通过定向token链接操作解耦为两种基本能力:结构化和概念化,并提出了一种端到端的统一抽取模型-USM,它联合编码提取模式和输入文本,并行统一提取子结构,并在需求时可控地解码目标结构。
结构化(Structuring):
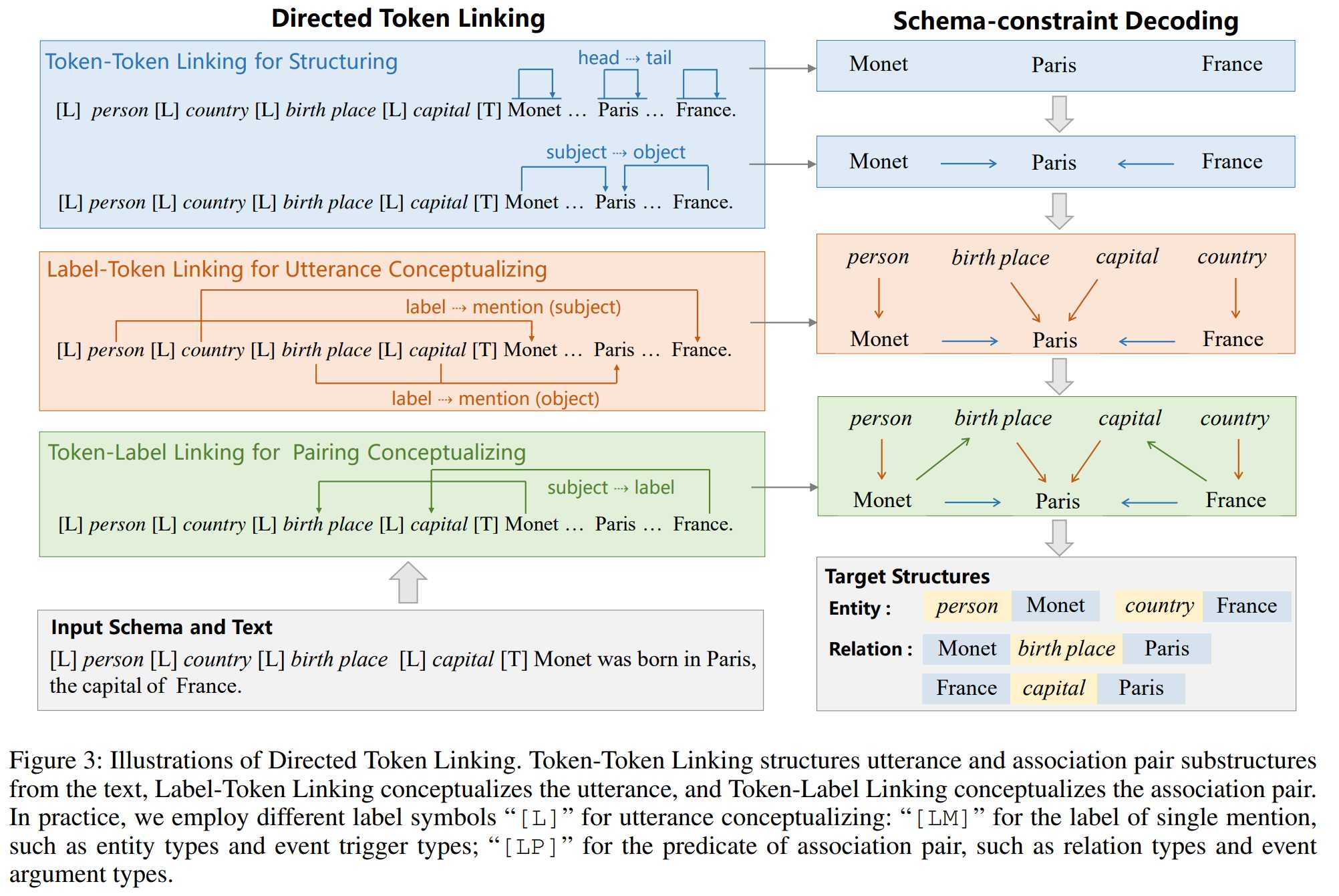
通过寻找输入文本中文本片段之间的语义关联 从文本中提取目标结构的基本子结构(与具体标签无关)。比如,从文本中提取出实体提及的话语结构“Monet”,事件提及的“born in”,以及关系提及的关联对结构(例如:“Monet”和“Paris”之间的关系),还有事件参数提及的结构(例如:“born in”和“Paris”之间的关系)。
话语(utterance):输入文本中的连续token序列
关联对(Association pair):从文本中提取出一对基本的相关单元
概念化(Conceptualizing):
寻找具体任务标签与上一步得到的子结构(话语结构与关联对结构)之间的语义匹配关系,使之与目标语义标签进行对应。
所有IE任务可以看做一系列结构化和概念化的组合,因此将所有IE转化为寻找话语结构(structure)和模式(scheme)之间的语义匹配。
要实现这一目标,有如下难点:
- 如何利用共享的结构化能力统一提取异构结构
- 如何在多样化的标签模式下统一表示不同的抽取任务,共享共同的概念化能力。
模型架构
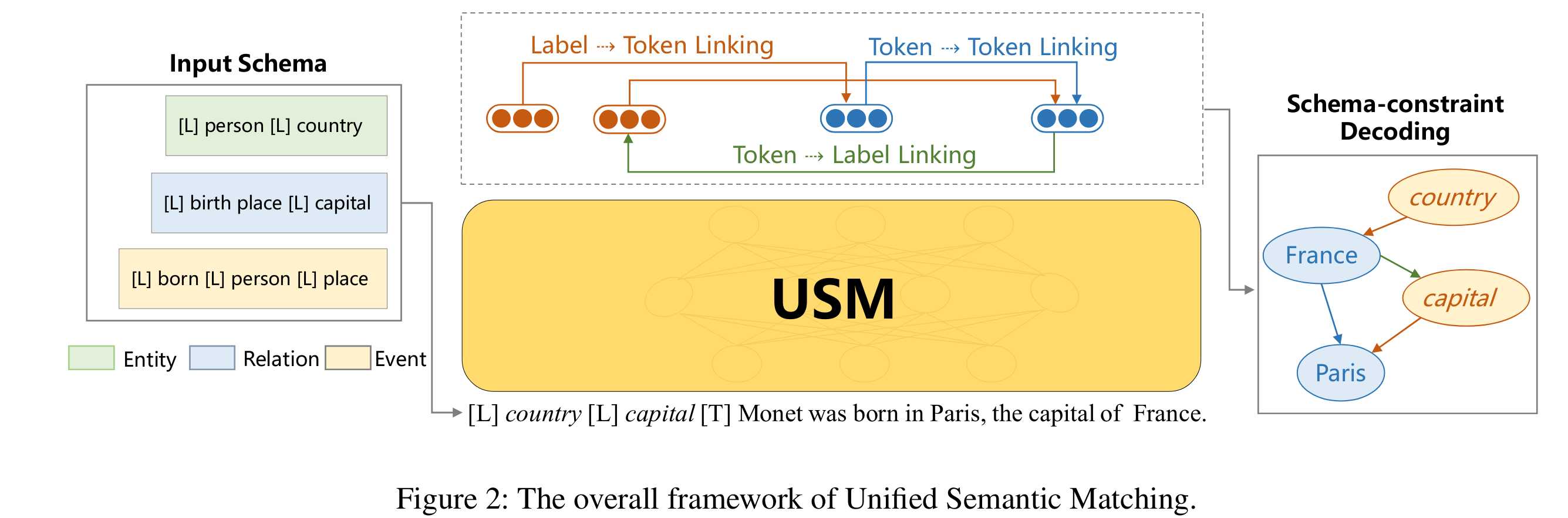
USM首先将所有标签模式(schema)进行了语言化处理,然后学习lable-token联合嵌入,构建标签文本的共享语义空间,然后用三种基本token连接操作从文本中结构化和概念化信息,最后通过模式约束解码完成最终抽取。
三种token连接操作:
1. 用于结构化的Token-Token连接:将单词头->单词尾提取文本词,将主体单词头->客体单词头连接文本对
构造(Subject, Object)
- 用于语义概念化的Label-Token连接:将标签单独提及的主体进行标签->单词头与标签->单词尾连接,以及对每个客体候选项通过同样的操作分配谓语类型,将标签->客体。
构造(Association, Object) -
用于关联对概念化的Token-Label连接:将三元组的主体与谓语类型进行单词头->标签和单词尾->标签的连接
构造(Subject, Association)
语言化处理是一种将抽象的标签模式转化为自然语言表达的过程,例如,如果我们有一个标签模式“Person → Work for → Organization”,语言化处理后可能变成“某人在某组织工作”,通过将标签模式和文本都转化为自然语言,我们可以在共享的语义空间中对它们进行联合编码,实现语义空间共享。
Schema-Text联合编码
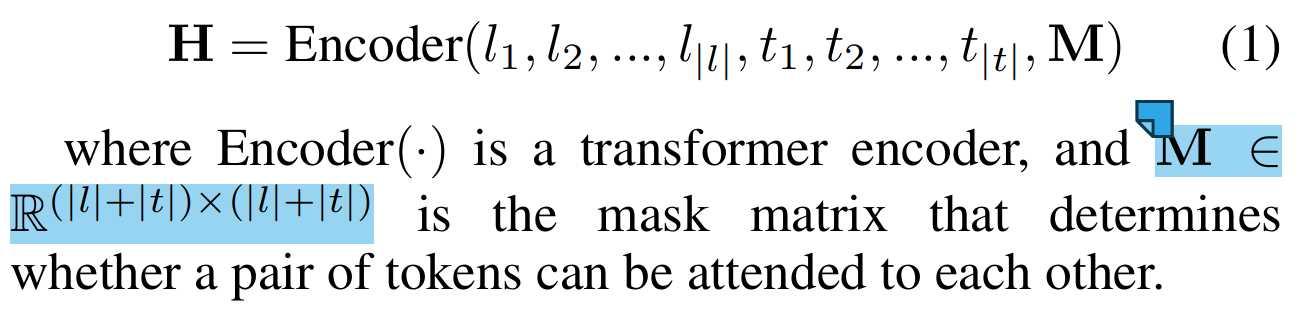
l是label的token序列,t是text的token序列,USM将抽取模式根据模式指导器SSI转换成token序列,然后与文本token拼接,同时加入掩码矩阵加强语义理解能力,然后输入编码器进行编码
结构化Token-Token连接
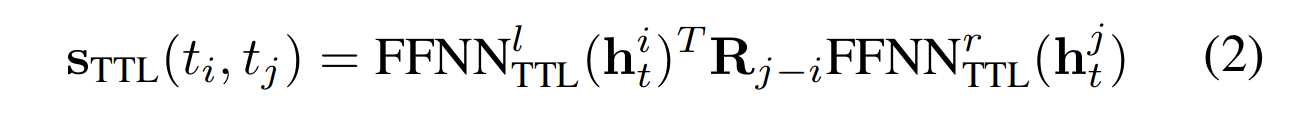
FFNN^l FFNN^t是两个前馈层,R_{j-i}是旋转位置嵌入向量。首先,对第i个标记和第j个标记的嵌入向量分别应用一个前馈神经网络(FFNNl TTL和FFNNr TTL),得到两个新的向量。
然后,根据第i个标记和第j个标记之间的相对位置,使用一个旋转位置嵌入(Rj−i)对其中一个向量进行变换,以注入位置信息。最后,计算两个向量的点积,得到标记-标记链接得分。这个公式通过计算第i个标记和第j个标记之间的token-token连接评估得分来进行文本词和文本对的抽取。
旋转位置嵌入是由论文《Rotary Embeddings: A Simple Universal Representation with Rotation Invariance》中提出的一种新型位置编码方法。它通过引入旋转变换来提高模型对序列中元素顺序的理解能力。
在旋转位置嵌入中,位置编码不再是简单的正弦或余弦函数,而是通过将位置信息与周期性的旋转变换相结合来生成。这种方法有助于模型学习到序列中元素之间的相对位置关系,同时具有旋转不变性,使得模型更具有泛化性。
语义概念化Label-Token连接

Label-Token Linking需要对文本中与标签相关的单独提及的词语和其他文本中客体候选词词语进行到标签的连接。我们让这两种连接任务用同一种到标签的连接方式,通过上下文加强模型的概念化能力。
同样的,通过计算label和text token的分数来指导连接。
关联对概念化Label-Token连接
因为上一连接任务进行了标签到谓语的连接,我们寻找关联对只要对剩下的主语词语与标签进行关联,因此,同样的我们计算剩下主语token与标签的分数,用H2L和T2L操作连接token和标签。
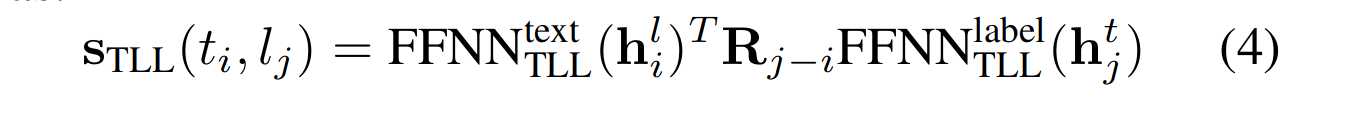
模式约束解码(Schema-constraint Decoding)
由于我们需要根据给定的抽取模式,从USM提取的子结构中选择合适的结果,从而生成最终的目标结构。
例如:对于输入的Schema[L] person [L] country [L] birth place [L] capital [T]和输入句子 Monet was born in Paris, the capital of France, 有:
首先经过Token-Token Linking, 抽取得到Monet, Paris, France, (Monet, Pairs), (France, Pairs).
然后通过Label-Token Linking, 得到(person, Monet), (country, France), (birth place, Paris), (capital, Paris), 这样就得到了Label对应的候选Object.
最后用Token-Label Linking, 得到(Monet, birth place), (France, capital), 完成Subject和Label的链接.
由于第一步, 抽取得到(Monet, birth place), (France, capital). 并且基于第一步的结果, 抽取得到两个三元组(Monet, birth place, Paris),(France, capital, Paris).
该过程中, 抽取是高度并行的, 第2, 3步解码需要依赖第1步解码的结果。
预训练
预训练任务
- 训练模型结构化和概念化的能力
- 训练模型解码的能力(?)
数据集
D_{task}:有标训练数据,也就是IE特定的数据。实体数据集,主要用于训练模型从文本中提取出实体提及的单词的能力。
包含任务注释,每个实例都有关于信息提取的黄金标注。使用了Ontonotes作为黄金标注,Ontonotes是信息提取领域广泛使用的数据集,其中包含18种实体类型。
D_{distant}:远程监督的关系分类数据集,由文本和知识库对齐的数据主要为了训练模型识别关系提及的关联对结构的能力。
远程监督是一种常见的做法,用于获取大规模的信息提取训练数据。每个实例都通过文本和知识库进行了对齐。作者使用了NYT和Rebel作为远程监督数据集,这些数据集是通过将文本与Freebase和Wikidata进行对齐而获得的。Rebel数据集具有大量的标签模式,而且所有的标签模式都太长,无法与输入文本连接并馈送到预训练的转换器编码器中。因此,作者对负标签模式进行了抽样,构建了元模式作为预训练的标签模式。
D_{indirect}:间接监督数据集,由其他可能与IE相关任务的数据组成。主要为了训练模型概念化的能力,提升模型理解语义间匹配的能力。
每个实例都是从其他相关的自然语言处理任务中得到的。作者利用了来自MRQA的阅读理解数据集作为间接监督数据集,包括HotpotQA、Natural Questions、NewsQA、SQuAD和TriviaQA。相比于Dtask和Ddistant中有限的实体类型和关系类型,Dindirect中的多样化问题表达可以为学习概念化提供更丰富的标签语义信息。对于Dindirect中的每个(question, context, answer)实例,作者将问题作为标签模式,上下文作为输入文本,答案作为提及。这通过学习标记-标记和标签-标记链接操作,在预训练阶段捕获了结构化和概念化能力。
预训练方法
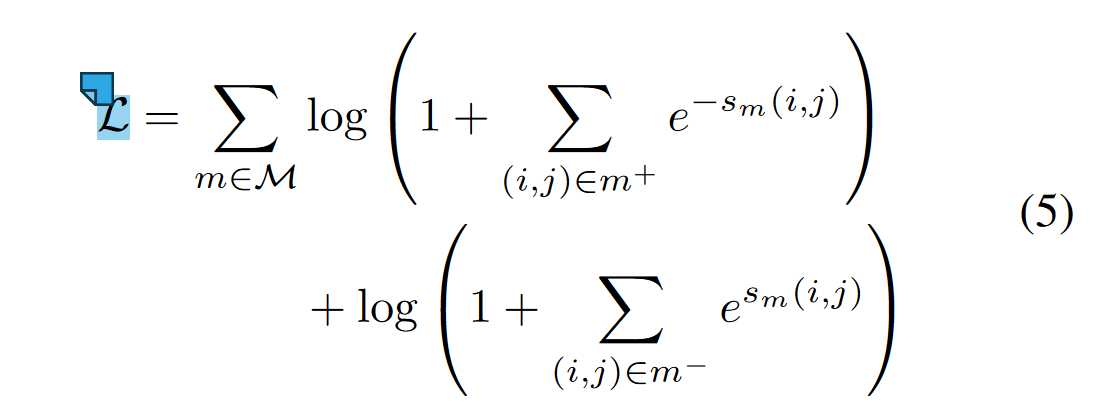
预训练主要问题是为了应对标记链接对的稀疏性(实际链接的令牌对的比例不到所有有效令牌对候选者的1%),因此作者引入类别不均衡损失,类别不平衡损失的思想是让模型对少数类别的样本给予更大的权重,从而减少少数类别的梯度下降的机会丢失。
这个公式中,M表示USM的链接类型,m+表示代表有链接的Token Pair,m−表示没有链接的Token Pair,s_m(i, j)代表Linking操作下Token Pair(i,j)之间的Linking得分。
具体来说,这个公式是由两部分组成的:第一部分是对所有链接对的损失求和,然后取对数。这个部分的目的是让模型尽量降低链接对的损失,也就是提高链接对的预测准确率。这个部分的损失是由每个链接对的负指数函数构成的,这样可以让损失在分数较高时变得很小,而在分数较低时变得很大。
第二部分是对所有非链接对的损失求和,然后取对数。这个部分的目的是让模型尽量增加非链接对的损失,也就是降低非链接对的预测准确率。这个部分的损失是由每个非链接对的正指数函数构成的,这样可以让损失在分数较高时变得很大,而在分数较低时变得很小。
这个公式的优点是可以动态地根据每个类别的难度来分配权重,而不是使用固定的权重或者采样技术。这样可以让模型更好地适应不同的类别不平衡程度,从而提高模型的泛化能力。
在特定IE Task上使用时, 还需要继续Finetune
实验
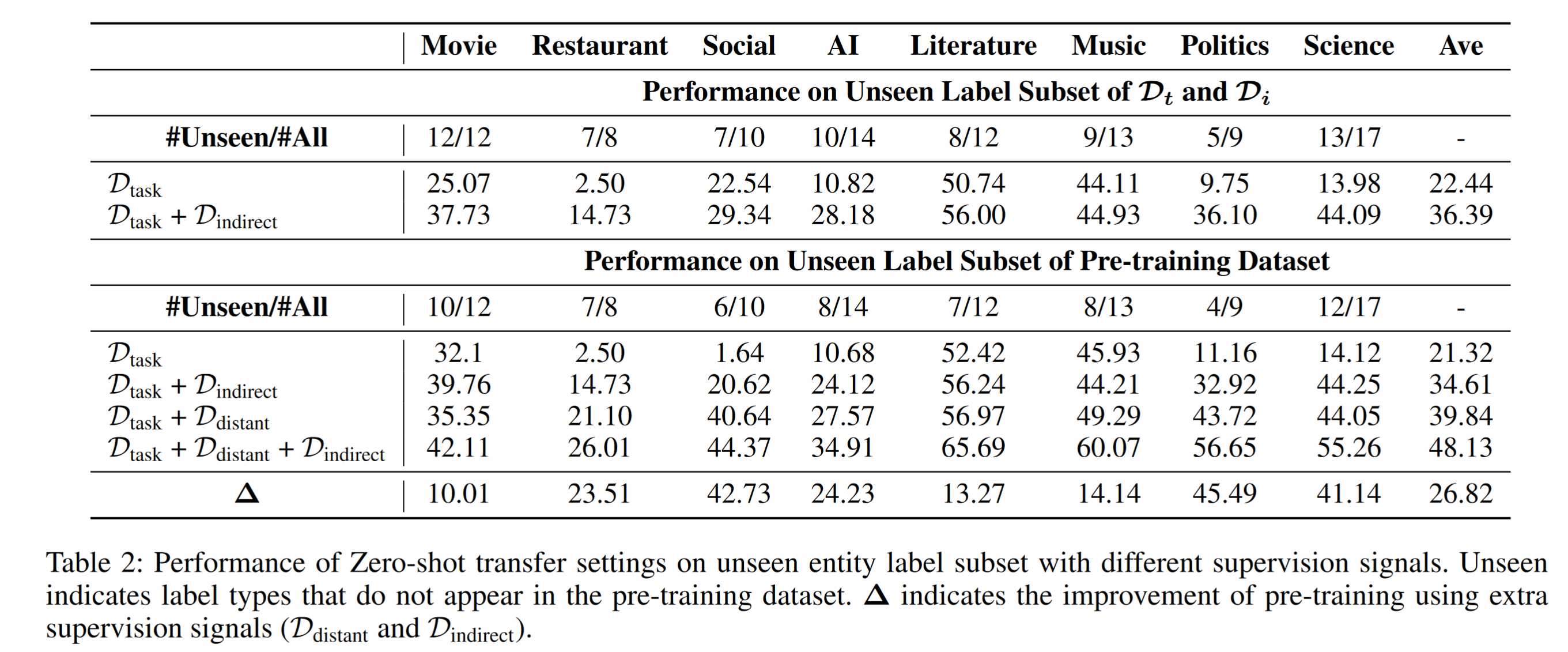
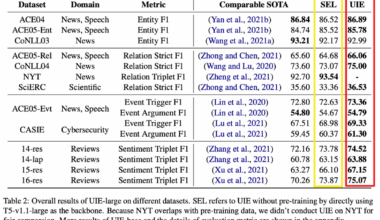
三个数据集一起使用,效果最好,表明数据集选择有效

从零样本性能可以看出,USM具有很强的跨标签零样本性能,表面模型具有很强的可迁移性,同时USM的参数数量少于其他两个模型,体现USM的模型高效。异构监督促进了统一标签语义理解和匹配能力,USM在所有数据集上都显著且一致地提高了性能。
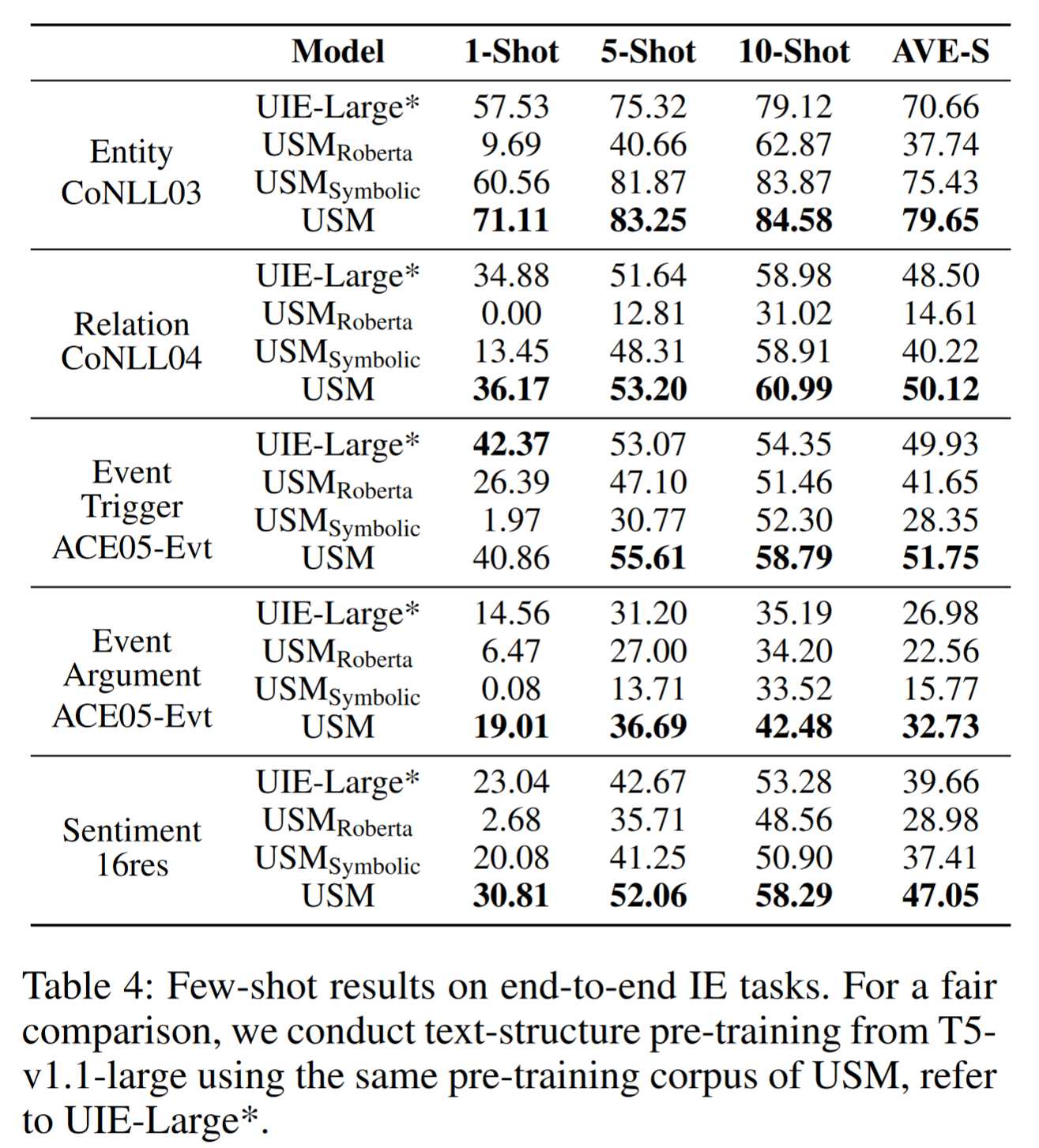
从实验结果可以看出,USM的效果总体优于其他模型。虽然UIE也采用动词化的标签表示,但迁移训练需要学习生成目标结构中的抽取模式词。相比之下,USM只需要学习匹配schema与span,缩小了解码搜索空间。
将抽取模式标签语义化非常重要,如果不了解标签语义,将会降低所有任务的性能。